Publications
Preprints
 |
Steering Robustness into World Action Models via Mechanistic Interpretability and Optimal Control Jihoon Hong*, Julian Skifstad*, Qiyue Dai, Alice Chan, Glen Chou June 2026. [Abstract] [arXiv] [PDF] [Project Website] [Code] [Video] [Cite] |
|
Abstract: World Action Models (WAMs) enable semantically- and physically-informed control but are brittle under distribution shift. In this work, we use mechanistic interpretability to study how robustness-relevant perturbations are represented in WAM activation space. Comparing activations across successful and unsuccessful rollouts, we find some WAM architectures exhibit low-dimensional linear separability for robustness-critical features, while others do not. This motivates the use of contrastive activation directions for training-free WAM steering. We also show that local linearity in WAM activation dynamics enables efficient feedback steering via model-based optimal control, yielding World-Action Linear Quadratic Regulator (WA-LQR), a minimally-invasive reduced-order LQR controller. Via mechanistic evaluations, we predict strong steerability in the Cosmos-Policy and DiT4DiT models but weak steerability in LingBot-VA, consistent with steering intervention results. On Cosmos-Policy and DiT4DiT, WA-LQR generalizes contrastive directions to new tasks and improves robustness to camera, gripper, and visual-noise perturbations over unsteered and prompt steering baselines. |
||
BibTeX:
@inproceedings{Hong26c, |
||
 |
Robustness without Wrinkles: Parallel Simulation and Robust MPC for Certified Deformable Manipulation Wei-Chen Li*, Jeffrey Fang*, Sasanka Polisetti, Yuexi Song, Glen Chou June 2026. [Abstract] [arXiv] [PDF] [Project Website] [Code] [Video] [Cite] |
|
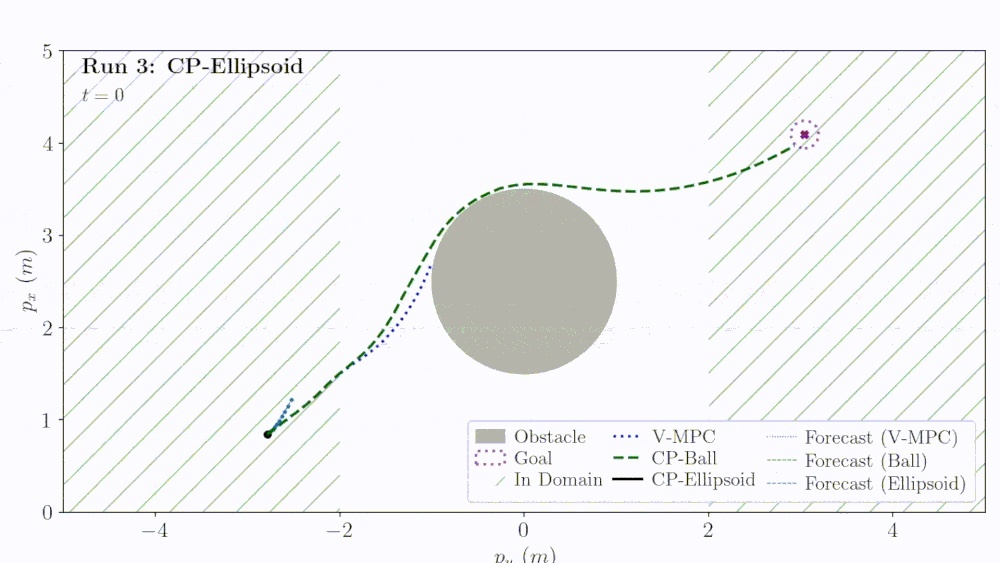
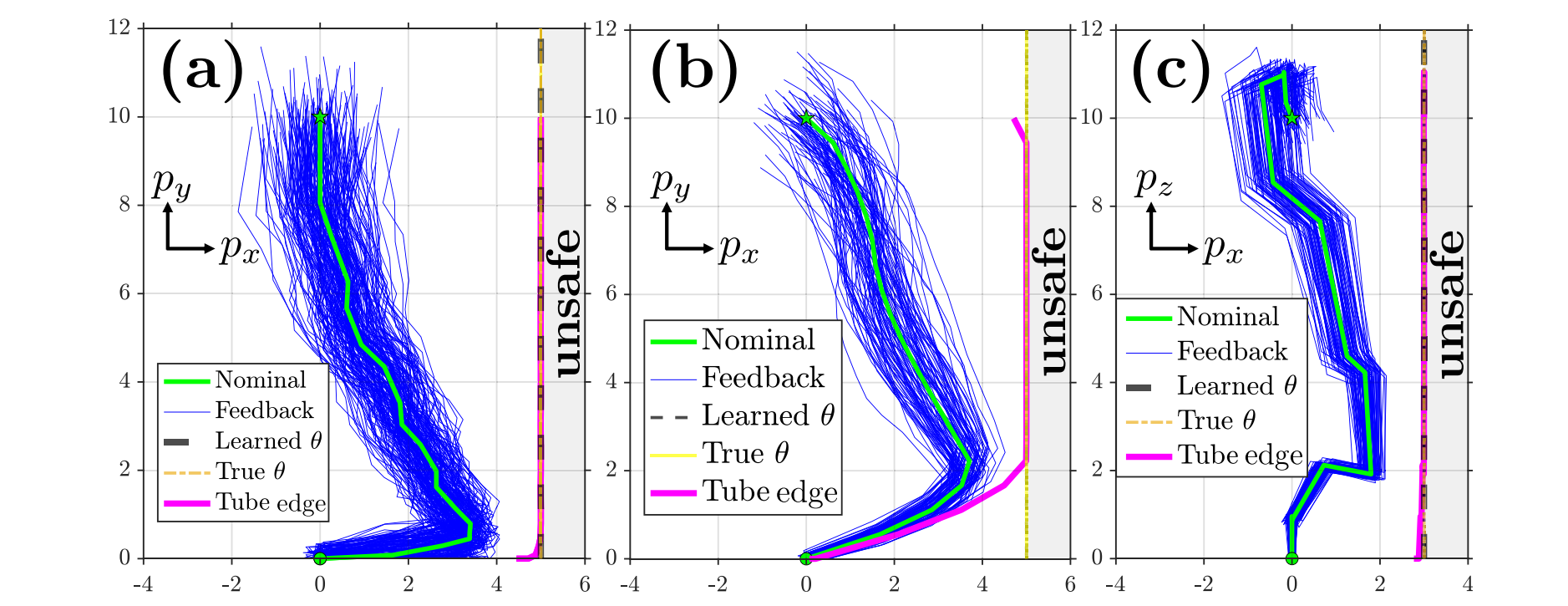
Abstract: We present CORD-SLS, a real-time control method for safe deformable object manipulation, with a focus on ropes and cloth. At its core is a GPU-parallel differentiable simulator with contact smoothing which enables efficient gradient-based planning through intermittent contact. To robustly satisfy constraints under model and sensing uncertainty, we develop a real-time, GPU-parallel output-feedback robust model predictive control (MPC) algorithm that plans with this simulator. We further show that the simulator accelerates model-based RL for training neural manipulation policies. To improve real-world robustness, we use conformal prediction to calibrate visual-feedback and perception-error bounds for MPC, producing reachable tubes that enable high-probability safe control. We evaluate CORD-SLS on high-dimensional, contact-rich rope and cloth manipulation tasks in simulation and hardware, including obstacle avoidance, routing, folding, and smoothing. Across settings, CORD-SLS achieves millisecond-speed planning, exceeding baselines in safety, speed, and task success. |
||
BibTeX:
@inproceedings{Li26c, |
||
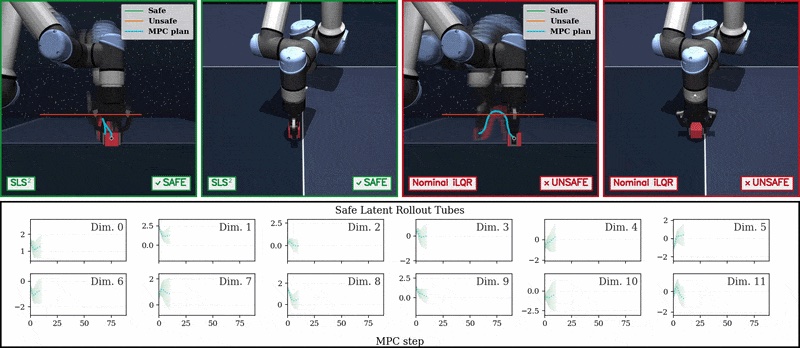 |
Pixels to Proofs: Probabilistically-Safe Latent World Model Control via Parallel Conformal Robust MPC Devesh Nath*, Anutam Srinivasan*, Haoran Yin*, Ruitong Jiang, Jeffrey Fang, Glen Chou June 2026. [Abstract] [arXiv] [PDF] [Project Website] [Code] [Video] [Cite] |
|
Abstract: We present SLS^2, a framework for safe feedback motion planning from pixels using robust model predictive control (MPC) in learned latent world models. Our approach trains an action-conditioned joint-embedding world model with compact Markovian latent states, enabling efficient gradient-based trajectory optimization through learned latent dynamics. To enforce safety for the true system despite imperfect latent predictions, we inform a GPU-accelerated system level synthesis (SLS) robust MPC scheme with conformal prediction to obtain calibrated latent error bounds and robust latent-space constraint sets. We further learn and conformalize a latent constraint checker, allowing the SLS planner to impose probabilistic safety constraints during closed-loop execution. We evaluate our method on vision-based control tasks, where it improves both goal-reaching performance and safety over latent world-model and safe-planning baselines. |
||
BibTeX:
@inproceedings{Nath26c, |
||
 |
ATLAS: A Large-Scale Evaluation Benchmark for Adversarial LiDAR Perception Mellon M. Zhang*, Siddhant Panse*, Zimo Fan, Akshal Dhal, Rishit Sarkar, Glen Chou June 2026. [Abstract] [arXiv] [PDF] [Cite] |
|
Abstract: Autonomous driving perception is typically evaluated on clean benchmark data, yet real-world deployment requires robustness to rare, structured, and potentially adversarial sensor anomalies. This gap is especially critical for LiDAR, where external actors can physically manipulate the sensing process to induce black-box perception failures without accessing the model. Existing LiDAR benchmarks provide little visibility into this failure mode. Prior adversarial LiDAR studies have largely centered on attack hardware, geometric and algorithmic defenses, and early-generation detectors, leaving the robustness of modern perception systems unexplored. To address this evaluation gap, we introduce ATLAS (Adversarial Temporal LiDAR Attack Suite), the first large-scale, physically grounded evaluation benchmark for LiDAR perception models under black-box sensor attacks, simulating the two primary attack modes -- point injection and point removal -- across real driving sequences. Evaluating a broad cross-section of current state-of-the-art LiDAR perception models, ATLAS reveals a surprising robustness asymmetry: models with stronger performance on standard benchmarks tend to better withstand removal attacks, yet are actually more vulnerable to injection attacks than weaker models. We trace this vulnerability to standard object database sampling augmentations, revealing how current training practices can induce architecture-agnostic robustness failures, and study initial directions for mitigating both attack modes. We release the ATLAS generation code to support extensible, reproducible evaluations as attack capabilities evolve, helping make black-box sensor robustness an explicit consideration in future LiDAR perception development. |
||
BibTeX:
@inproceedings{Zhang26c, |
||
 |
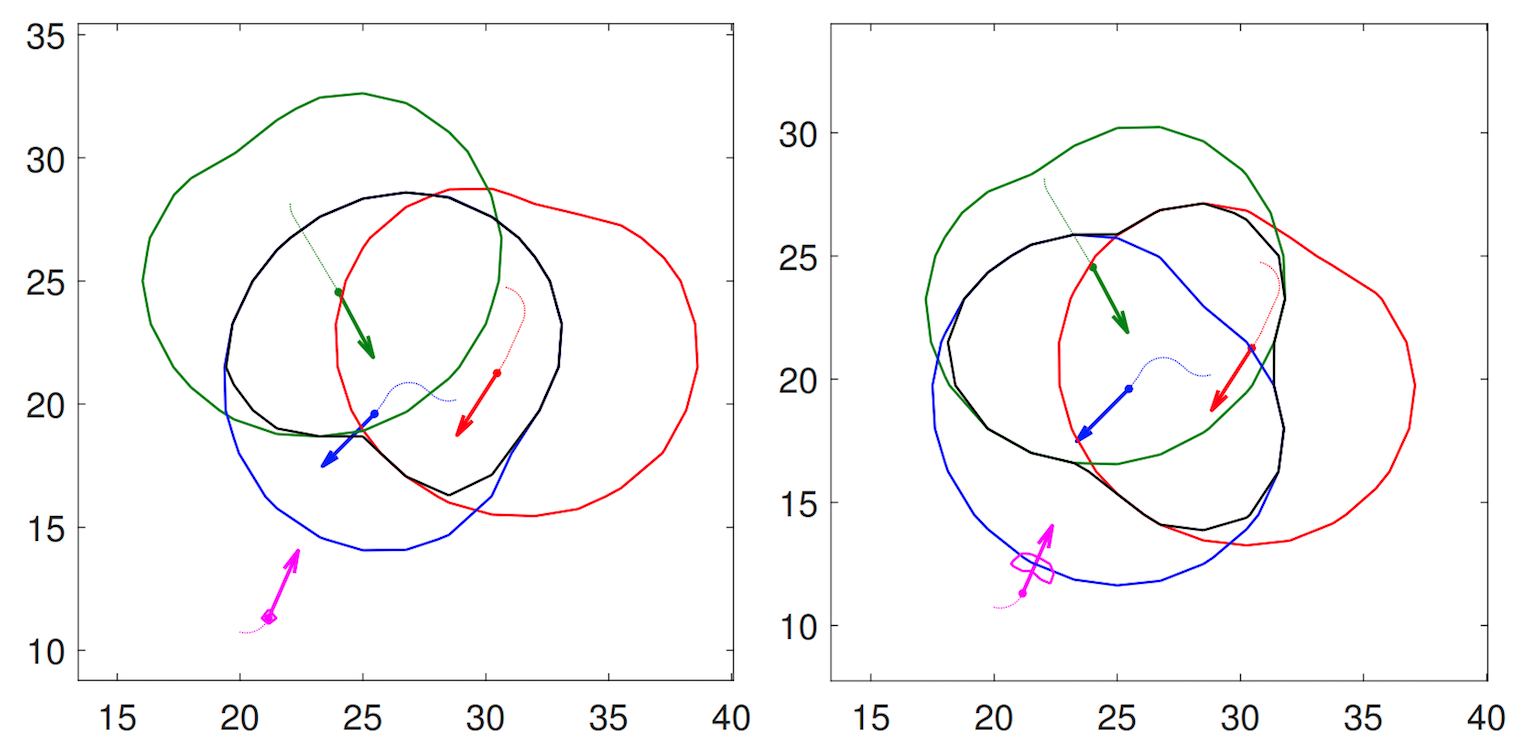
Activation Steering of Video Generation Models via Reduced-Order Linear Optimal Control Jihoon Hong, Alice Chan*, Qiyue Dai*, Julian Skifstad, Glen Chou June 2026. [Abstract] [arXiv] [PDF] [Cite] |
|
Abstract: Text-to-video (T2V) models trained on large-scale web data can generate undesired content, motivating interventions that reduce harmful outputs without sacrificing visual quality. Activation steering offers an attractive mechanistic alternative to finetuning and prompt filtering, but existing T2V steering methods remain limited, typically applying coarse, non-anticipative interventions that can lead to oversteering and content degradation. To close this gap, we propose Latent Activation Linear-Quadratic Regulator (LA-LQR), a reduced-order optimal control framework for minimally invasive T2V steering. LA-LQR formulates T2V inference as a dynamical system and computes closed-loop feedback interventions that steer activations toward desired feature setpoints while penalizing unnecessary perturbations. To make optimal control feasible for high-dimensional video activations, we project activations onto a low-dimensional, task-relevant subspace derived from contrastive prompt pairs, estimate local linear dynamics in this latent space, and solve a latent LQR problem to obtain timestep- and layer-specific steering signals. We provide theoretical bounds relating latent setpoint tracking to raw activation-space feature control, and empirically validate the fidelity of the reduced latent dynamics. On concept steering and video safety benchmarks, LA-LQR reduces unsafe generations relative to baselines, while preserving prompt fidelity and visual quality. |
||
BibTeX:
@inproceedings{Hong26b, |
||
 |
Safe, Real-Time Active Model Discrimination and Fault Diagnosis for Nonlinear Systems via Differentiable Reachability Xinpei Ni, Melkior Ornik, Glen Chou, Samuel Coogan June 2026. [Abstract] [arXiv] [PDF] [Cite] |
|
Abstract: We present a safe, real-time algorithm for active fault diagnosis and model discrimination for uncertain continuous-time nonlinear systems with process and measurement disturbances. Given a finite set of candidate models representing nominal and faulty modes, including actuator and sensor faults, we formulate an output-feedback, time-varying policy optimization problem that (i) robustly enforces state-input safety constraints over a finite horizon and (ii) drives the system to produce sampled measurements consistent with at most one model, enabling deterministic diagnosis. To solve this problem in real time, we develop a tractable approximation using interval over-approximations of reachable state and output sets, and encode diagnosability via a differentiable objective that penalizes overlap between the reachable output sets of possible models. The resulting optimization is solved efficiently online with gradient-based methods using JAX and differentiable reachability primitives. We evaluate our method on sensor and actuator fault diagnosis (up to 11 fault modes) in several high-dimensional nonlinear robotic systems, including a simulated quadrotor and fighter-jet model, a hardware differential-drive robot, and quadrupedal navigation. Across these case studies, our approach achieves reliable model discrimination in under 50 ms, outperforming baselines in discrimination success rate and speed while providing formal safety guarantees. |
||
BibTeX:
@inproceedings{Ni26, |
||
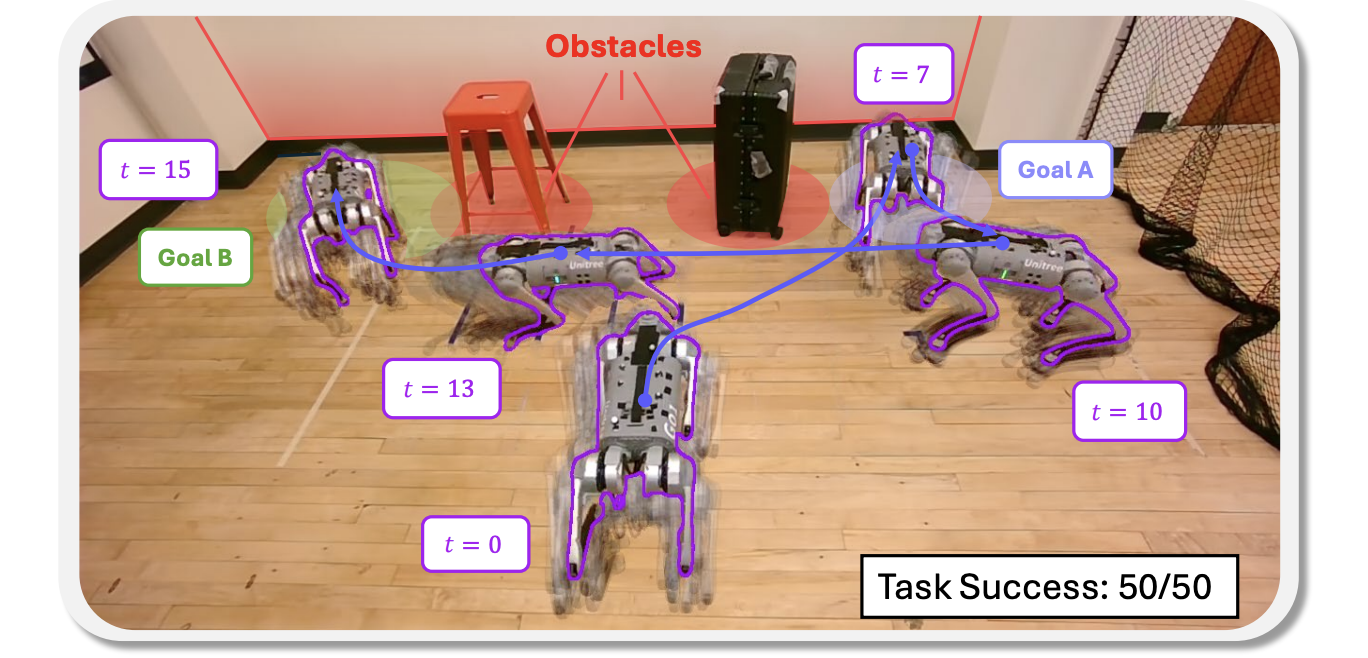 |
Feedback Motion Planning for Stochastic Nonlinear Systems with Signal Temporal Logic Specifications Liqian Ma*, Zishun Liu*, Glen Chou, Yongxin Chen April 2026. [Abstract] [arXiv] [PDF] [Cite] |
|
Abstract: We study feedback motion planning for continuous-time stochastic nonlinear systems under signal temporal logic (STL) specifications. We propose a framework that synthesizes control policies for chance-constrained STL trajectory optimization problems, with the goal of ensuring that the closed-loop stochastic system satisfies a given STL formula with high probability (e.g., 99.99\%). Our approach is based on a predicate erosion strategy that transforms the intractable stochastic problem into a deterministic STL trajectory optimization problem with tightened STL formula constraints. The amount of erosion is determined by a probabilistic reachable tube (PRT) that bounds the deviation between the stochastic trajectory and an associated nominal trajectory. To compute such bounds, we leverage contraction theory and feedback design, and develop several tracking controllers. This yields a complete feedback motion planning pipeline which can be implemented by numerical optimizations. We demonstrate the efficacy and versatility of the proposed framework through simulations on several robotic systems and through experiments on a real-world quadrupedal robot, and show that it is less conservative and achieves higher specification satisfaction probability than representative baselines. |
||
BibTeX:
@inproceedings{Gould26, |
||
Journal and Conference Papers
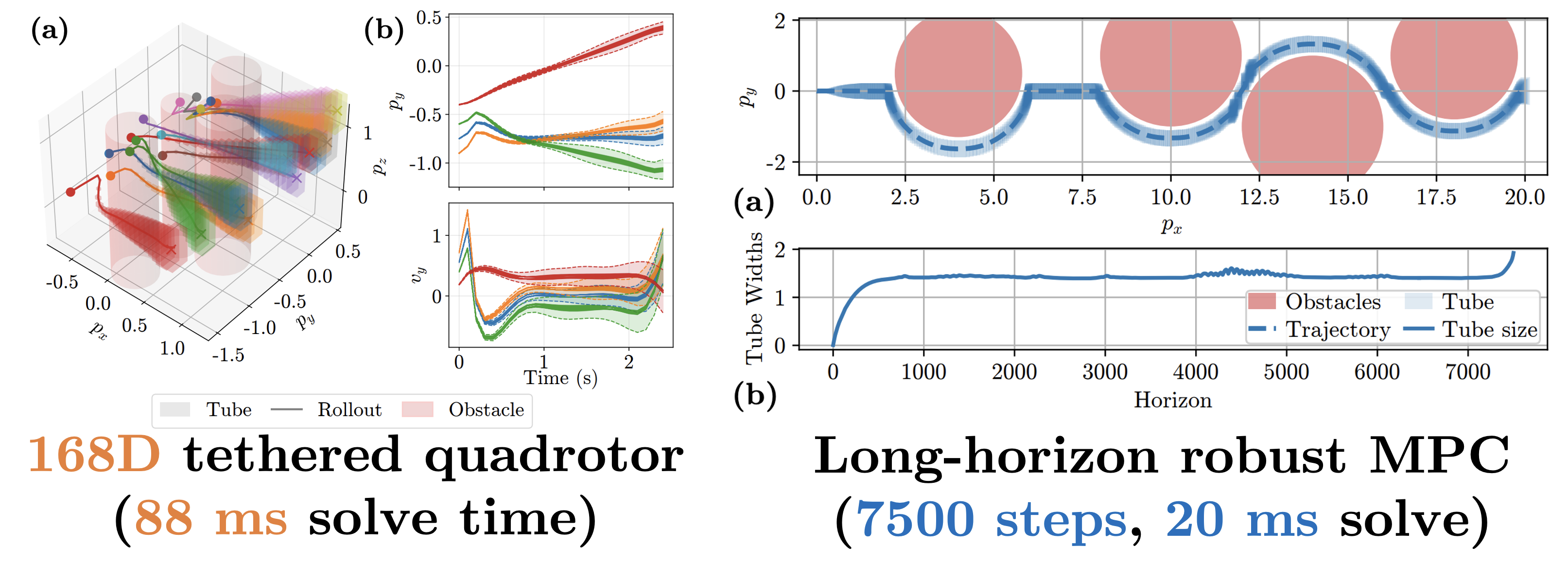 |
[C33] | GPU-Parallel Linearization Error Bounds for Real-Time Robust Optimal Control of Nonlinear and Neural Network Dynamics Jeffrey Fang*, Keyi Shen*, Anutam Srinivasan, Glen Chou Proceedings of the 65th IEEE Conference on Decision and Control (CDC), December 2026. [Abstract] [arXiv] [PDF] [Project Website] [Code] [Cite] |
Abstract: This paper studies real-time robust optimal control for uncertain nonlinear systems, where linear time-varying (LTV) approximations make planning tractable but require sound linearization error bounds (LEBs) to guarantee robust constraint satisfaction. We develop tight, differentiable, GPU-parallel LEBs for LTV approximations of nonlinear and neural network (NN) dynamics. For analytic dynamics, we introduce path-based Hessian bounds that are tighter than standard interval methods. For NN dynamics, we derive certified LEBs using NN verifier-generated affine relaxations and local Jacobian corrections. We adapt a GPU-parallel system-level synthesis LTV-based robust control solver to be compatible with these LEBs by extending it to handle right-invertible disturbance matrices and non-zero-centered disturbance sets for tight zonotopic uncertainty propagation. Our method, GPUSLS-LEO, enables online optimization of robust feedback policies that account for linearization error, producing tight, formally verified reachable tubes. On complex nonlinear and NN dynamics up to 168 state dimensions, our method can compute robust control policies on the GPU at rates up to 67 Hz, reducing solve times and conservativeness relative to baselines while preserving formal guarantees and real-time performance. |
||
BibTeX:
@inproceedings{Fang26b, |
||
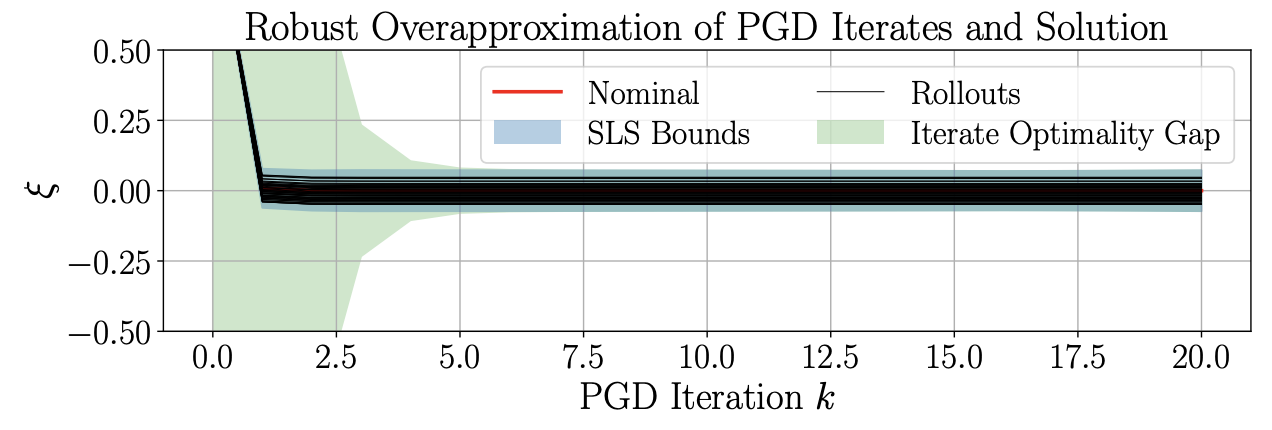 |
[C32] | Over-Approximating Minimizer Sets of Constrained Convex Programs with Parametric Uncertainty via Reachability Analysis Brendan Gould*, Chih-Yuan Chiu*, Antoine P. Leeman, Kyriakos G. Vamvoudakis, Samuel Coogan, Glen Chou Proceedings of the 65th IEEE Conference on Decision and Control (CDC), December 2026. [Abstract] [arXiv] [PDF] [Cite] |
Abstract: We study the set of solutions to a parameterized, strongly convex optimization problem whose cost depends on uncertain, bounded parameters. We compute a certified outer approximation of the corresponding set of optimizers, using convergence properties of the projected gradient descent (PGD) algorithm for convex programs. Concretely, by treating the cost parameter as constant but unknown, we interpret the PGD iterates as an uncertain dynamical system and analyze its forward reachable sets. Since PGD converges exponentially to the unique optimizer for each fixed parameter, these reachable sets provide outer approximations of the optimizer set, with an explicit error bound that decays exponentially with the iteration count. We apply system-level synthesis (SLS) on the PGD dynamics to optimize the step-size sequence and obtain reachable-set over-approximations. Our method outperforms existing baselines in over-approximating, with low conservativeness, the minimizer sets of convex programs with uncertain costs and high-dimensional decision variables. |
||
BibTeX:
@inproceedings{Gould26, |
||
 |
[J9] |
PolyMerge: Compressing 3D Gaussian Splats with Polytope Coverings for Provably Safe Resource-Constrained Navigation Jihoon Hong, Chih-Yuan Chiu, Sara Fridovich-Keil, Glen Chou IEEE Robotics and Automation Letters (RA-L), with presentation at IROS 2026, vol. 11, no. 7, pp. 8512-8519, July 2026. [Abstract] [arXiv] [PDF] [DOI] [Project Website] [Code] [Supplementary Video] [Cite] |
Abstract: Obstacle avoidance is essential for safe navigation and motion planning. Recent advances in radiance field reconstruction have enabled object detection and modeling with unprecedented fidelity, but remain too memory- and compute-intensive for deployment in on-board perception-based motion planning. To address these limitations, we propose PolyMerge to transform a large, photorealistic 3D Gaussian Splatting (3DGS) model of a scene into a lightweight representation as a set of convex polytopes whose enclosed volume is guaranteed to over-approximate all obstacles in the original 3DGS model. PolyMerge uses a variable number of polytopes to trade off conservativeness and computational cost, and integrates with polytope-based control barrier functions (CBFs) to ensure collision-free path planning. We showcase PolyMerge in simulation and hardware experiments using a small Crazyflie drone, which uses PolyMerge to compute and follow safe trajectories in real time using extremely limited onboard compute resources, outperforming baselines in speed while guaranteeing safety. |
||
BibTeX:
@inproceedings{Hong-RAL-26, |
||
 |
[C31] |
Local Linearity of LLMs Enables Activation Steering via Model-Based Linear Optimal Control Julian Skifstad, Xinyue Annie Yang, Glen Chou Proceedings of the 43rd International Conference on Machine Learning (ICML), July 2026. [Abstract] [arXiv] [PDF] [Project Website] [Code] [Video] [Cite] |
Abstract: Inference-time LLM alignment methods, particularly activation steering, offer an alternative to fine-tuning by directly modifying activations during generation. Existing methods, however, often rely on non-anticipative interventions that ignore how perturbations propagate through transformer layers and lack online error feedback, resulting in suboptimal, open-loop control. To address this, we show empirically that, despite the nonlinear structure of transformer blocks, layer-wise dynamics across multiple LLM architectures and scales are well-approximated by locally-linear models. Exploiting this property, we model LLM inference as a linear time-varying dynamical system and adapt the classical linear quadratic regulator to compute feedback controllers using layer-wise Jacobians, steering activations toward desired semantic setpoints in closed-loop with minimal computational overhead and no offline training. We also derive theoretical bounds on setpoint tracking error, enabling formal guarantees on steering performance. Using a novel adaptive semantic feature setpoint signal, our method yields robust, fine-grained behavior control across models, scales, and tasks, including state-of-the-art modulation of toxicity, truthfulness, refusal, and arbitrary concepts, surpassing baseline steering methods. |
||
BibTeX:
@inproceedings{Skifstad-ICML-26, |
||
 |
[C30] |
Safe Large-Scale Robust Nonlinear MPC in Milliseconds via Reachability-Constrained System Level Synthesis on the GPU Jeffrey Fang, Glen Chou Proceedings of Robotics: Science and Systems (RSS) XXII, July 2026. [Abstract] [arXiv] [PDF] [Project Website] [Code] [Video] [Cite] |
Abstract: We present GPU-SLS, a GPU-parallelized framework for safe, robust nonlinear model predictive control (MPC) that scales to high-dimensional uncertain robotic systems and long planning horizons. Our method jointly optimizes an inequality-constrained, dynamically-feasible nominal trajectory, a tracking controller, and a closed-loop reachable set under disturbance, all in real-time. To efficiently compute nominal trajectories, we develop a sequential quadratic programming procedure with a novel GPU-accelerated quadratic program (QP) solver that uses parallel associative scans and adaptive caching within an alternating direction method of multipliers (ADMM) framework. The same GPU QP backend is used to optimize robust tracking controllers and closed-loop reachable sets via system level synthesis (SLS), enabling reachability-constrained control in both fixed- and receding-horizon settings. We achieve substantial performance gains, reducing nominal trajectory solve times by 97.7% relative to state-of-the-art CPU solvers and 71.8% compared to GPU solvers, while accelerating SLS-based control and reachability by 237x. Despite large problem scales, our method achieves 100% empirical safety, unlike high-dimensional learning-based reachability baselines. We validate our approach on complex nonlinear systems, including whole-body quadrupeds (61D) and humanoids (75D), synthesizing robust control policies online on the GPU in 20 milliseconds on average and scaling to problems with 2 x 10^5 decision variables and 8 x 10^4 constraints. |
||
BibTeX:
@inproceedings{Fang-RSS-26, |
||
 |
[C29] |
Certified Gradient-Based Contact-Rich Manipulation via Smoothing-Error Reachable Tubes Wei-Chen Li, Glen Chou Proceedings of Robotics: Science and Systems (RSS) XXII, July 2026. [Abstract] [arXiv] [PDF] [Project Website] [Code] [Video] [Cite] |
Abstract: Gradient-based methods can efficiently optimize controllers using physical priors and differentiable simulators, but contact-rich manipulation remains challenging due to discontinuous or vanishing gradients from hybrid contact dynamics. Smoothing the dynamics yields continuous gradients, but the resulting model mismatch can cause controller failures when executed on real systems. We address this trade-off by planning with smoothed dynamics while explicitly quantifying and compensating for the induced errors, providing formal guarantees of constraint satisfaction and goal reachability on the true hybrid dynamics. Our method smooths both contact dynamics and geometry via a novel differentiable simulator based on convex optimization, which enables us to characterize the discrepancy from the true dynamics as a set-valued deviation. This deviation constrains the optimization of time-varying affine feedback policies through analytical bounds on the system's reachable set, enabling robust constraint satisfaction guarantees for the true closed-loop hybrid dynamics, while relying solely on informative gradients from the smoothed dynamics. We evaluate our method on several contact-rich tasks, including planar pushing, object rotation, and in-hand dexterous manipulation, achieving guaranteed constraint satisfaction with lower safety violation and goal error than baselines. By bridging differentiable physics with set-valued robust control, our method is the first certifiable gradient-based policy synthesis method for contact-rich manipulation. |
||
BibTeX:
@inproceedings{Li-RSS-26, |
||
 |
[C28] |
Parallel Differentiable Reachability for Learning and Planning with Certified Neural Dynamics and Controllers Keyi Shen, Glen Chou Proceedings of Robotics: Science and Systems (RSS) XXII, July 2026. [Abstract] [arXiv] [PDF] [Project Website] [Code (DiffReach)] [Code (DiffReach-Robotics)] [Video] [Cite] |
Abstract: Neural network (NN) dynamics models and control policies achieve strong performance in robotics, but providing sound guarantees under uncertainty is difficult, especially when the NNs are components within the closed-loop system. Existing reachability tools offer formal over-approximations, yet are often non-differentiable, overly conservative, and too slow to integrate into modern learning and real-time planning pipelines. To address this, we present a parallelizable, differentiable reachability analysis tool in JAX that unifies continuous- and discrete-time systems and supports both analytical and NN-based dynamics and controllers. Our reachability tool uses Taylor-model flowpipe construction and CROWN-style linear bound relaxation and propagation, yielding a GPU-batched reachability primitive that can be differentiated and used in downstream objectives. Building on this primitive, we design (i) a certified training method that encourages the learning of reachability-friendly dynamics models and controllers, and (ii) a reachability-informed sampling-based MPC scheme that incorporates certified reachable sets during action selection and enables gradient-based refinement. Experiments on non-prehensile object manipulation and quadrotor control tasks show competitive performance to baseline planners while providing tight, certified reachability guarantees under uncertainty. |
||
BibTeX:
@inproceedings{Shen-RSS-26, |
||
 |
[C27] |
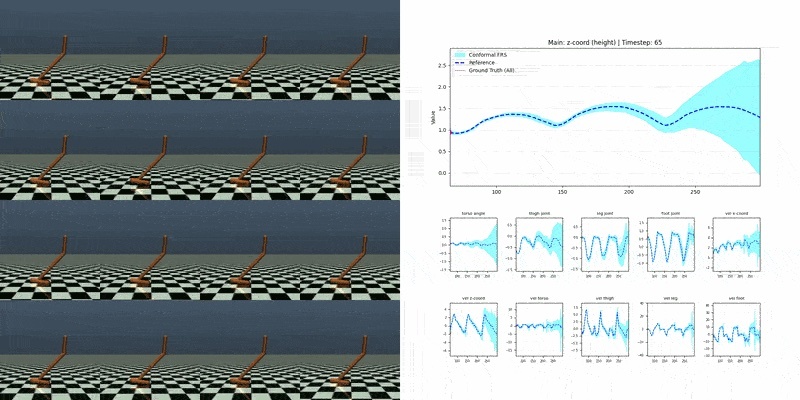
VISION-SLS: Safe Perception-Based Control from Learned Visual Representations via System Level Synthesis Antoine Leeman*, Shuyu Zhan*, Melanie Zeilinger, Glen Chou Proceedings of Robotics: Science and Systems (RSS) XXII, July 2026. [Abstract] [arXiv] [PDF] [Project Website] [Code] [Video] [Cite] |
Abstract: We propose VISION-SLS, a method for nonlinear output-feedback control from high-resolution RGB images which provides robust constraint satisfaction guarantees under calibrated uncertainty bounds despite partial observability, sensor noise, and nonlinear dynamics. To enable scalability while retaining guarantees, we propose: (i) a learned low-dimensional observation map from pretrained visual features with state-dependent error bounds, and (ii) a causal affine time-varying output-feedback policy optimized via System Level Synthesis (SLS). We develop a scalable, novel solver for the resulting nonconvex program that leverages sequential convex programming coupled with efficient Riccati recursions. On two simulated visuomotor tasks (a 4D car and a 10D quadrotor) with >= 512 x 512 pixels and a 59D humanoid task with partial observability, our method enables safe, information-gathering behavior that reduces uncertainty while guaranteeing constraint satisfaction with empirically-calibrated error bounds. We also validate our method on hardware, safely controlling a ground vehicle from onboard images, outperforming baselines in safety rate and solve times. Together, these results show that learned visual abstractions coupled with an efficient solver make SLS-based safe visuomotor output-feedback practical at scale. |
||
BibTeX:
@inproceedings{Leeman-RSS-26, |
||
 |
[C26] |
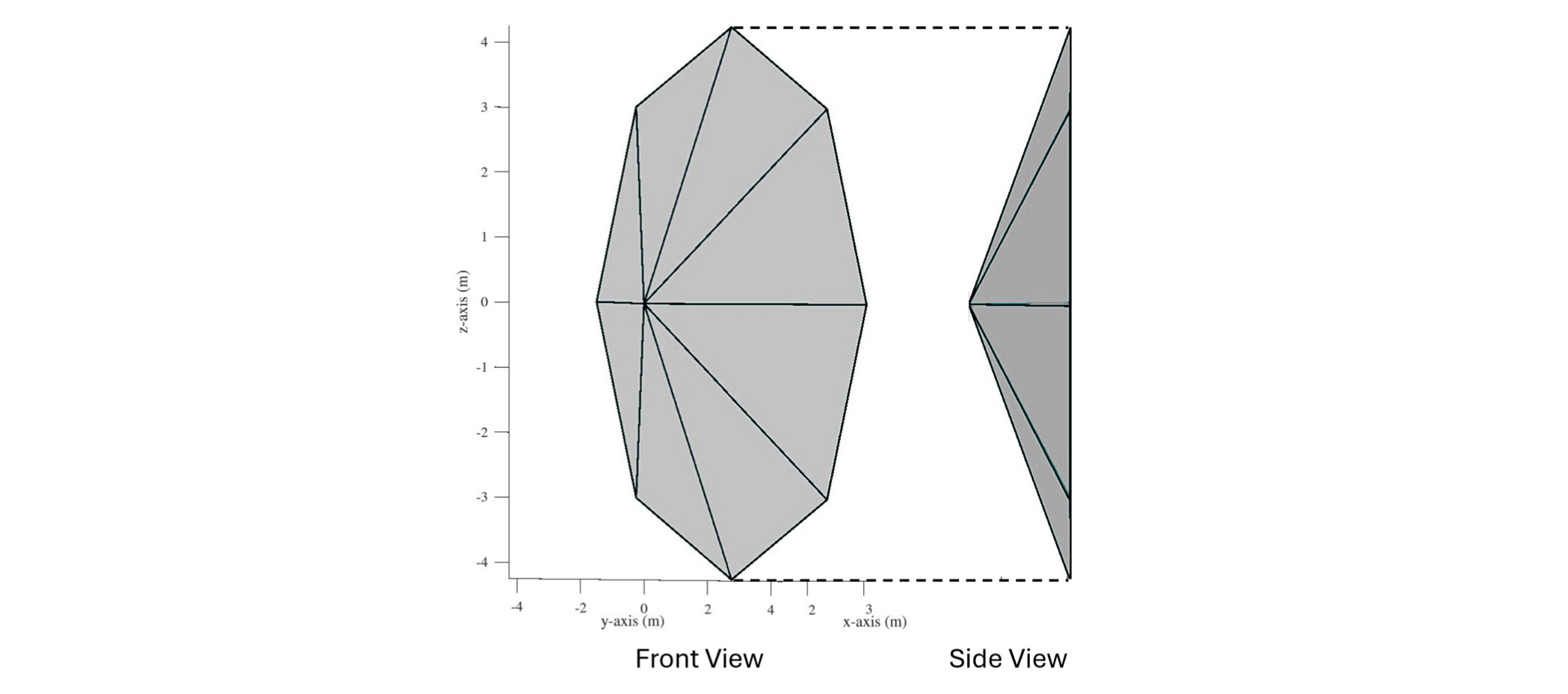
Design and Trajectory Optimization of a Shape-Morphing Aeroshell for Skip-Entry Orbital Inclination Change Abinay Brown, Glen Chou Proceedings of the 27th AIAA International Space Planes and Hypersonic Systems and Technologies Conference, July 2026. [Abstract] [PDF] [DOI] [Cite] |
Abstract: This paper addresses the gap between the theoretical efficiency of skip-entry maneuvers for orbital inclination change and the practical difficulty of achieving the high lift-to-drag (L/D) ratios required with conventional rigid aeroshells. We propose a modular, shape-morphing aeroshell that attaches to an existing spacecraft and uses actuated arms to vary its geometry, enabling active control of aerodynamic coefficients during hypersonic skip. We model the shape-morphing aerodynamics, equations of motion, Δ𝑖 and Δ𝑉 relationships for skip-entry, and formulate an optimal control problem to determine arm deflections, angles of attack, and bank angles that minimize total Δ𝑉 while achieving a desired inclination change Δ𝑖. Our results show practical Δ𝑉 reductions of 24–38% for Δ𝑖 = 0◦ to 18◦, and approximately 40% for large changes of 28.5◦ and 47.1◦, corresponding to transfers from 𝑖 = 70◦ and 𝑖 = 51.6◦ to sun-synchronous orbit (𝑖 = 98.5◦), compared to pure propulsive plane change. |
||
BibTeX:
@inproceedings{Brown-Hypersonics-26, |
||
 |
[C25] |
Scalable Data-Driven Reachability Analysis and Control via Koopman Operators with Conformal Coverage Guarantees Devesh Nath*, Haoran Yin*, Glen Chou Proceedings of the 8th Annual Learning for Dynamics & Control Conference (L4DC), June 2026. [Abstract] [arXiv] [PDF] [Cite] Best paper finalist (top 1.8% of submissions). |
Abstract: We propose a scalable reachability-based framework for probabilistic, data-driven safety verification of unknown nonlinear dynamics. We use Koopman theory with a neural network (NN) lifting function to learn an approximate linear representation of the dynamics and design linear controllers in this space to enable closed-loop tracking of a reference trajectory distribution. Closed-loop reachable sets are efficiently computed in the lifted space and mapped back to the original state space via NN verification tools. To capture model mismatch between the Koopman dynamics and the true system, we apply conformal prediction to produce statistically-valid error bounds that inflate the reachable sets to ensure the true trajectories are contained with a user-specified probability. These bounds generalize across references, enabling reuse without recomputation. Results on high-dimensional MuJoCo tasks (11D Hopper, 28D Swimmer) and 12D quadcopters show improved reachable set coverage rate, computational efficiency, and conservativeness over existing methods. |
||
BibTeX:
@inproceedings{Nath-L4DC-26, |
||
 |
[C24] |
Safety Beyond the Training Data: Robust Out-of-Distribution MPC via Conformalized System Level Synthesis Anutam Srinivasan, Antoine Leeman, Glen Chou Proceedings of the 8th Annual Learning for Dynamics & Control Conference (L4DC), June 2026. [Abstract] [arXiv] [PDF] [Cite] |
Abstract: We present a novel framework for robust out-of-distribution planning and control using conformal prediction (CP) and system level synthesis (SLS), addressing the challenge of ensuring safety and robustness when using learned dynamics models beyond the training data distribution. We first derive high-confidence model error bounds using weighted CP with a learned, state-control-dependent covariance model. These bounds are integrated into an SLS-based robust nonlinear model predictive control (MPC) formulation, which performs constraint tightening over the prediction horizon via volume-optimized forward reachable sets. We provide theoretical guarantees on coverage and robustness under distributional drift, and analyze the impact of data density and trajectory tube size on prediction coverage. Empirically, we demonstrate our method on nonlinear systems of increasing complexity, including a 4D car and a {12D} quadcopter, improving safety and robustness compared to fixed-bound and non-robust baselines, especially outside of the data distribution. |
||
BibTeX:
@inproceedings{Srinivasan-L4DC-26, |
||
 |
[C23] |
Active Constraint Learning in High Dimensions from Demonstrations Zheng Qiu, Chih-Yuan Chiu, Glen Chou Proceedings of the 8th Annual Learning for Dynamics & Control Conference (L4DC), June 2026. [Abstract] [arXiv] [PDF] [Cite] |
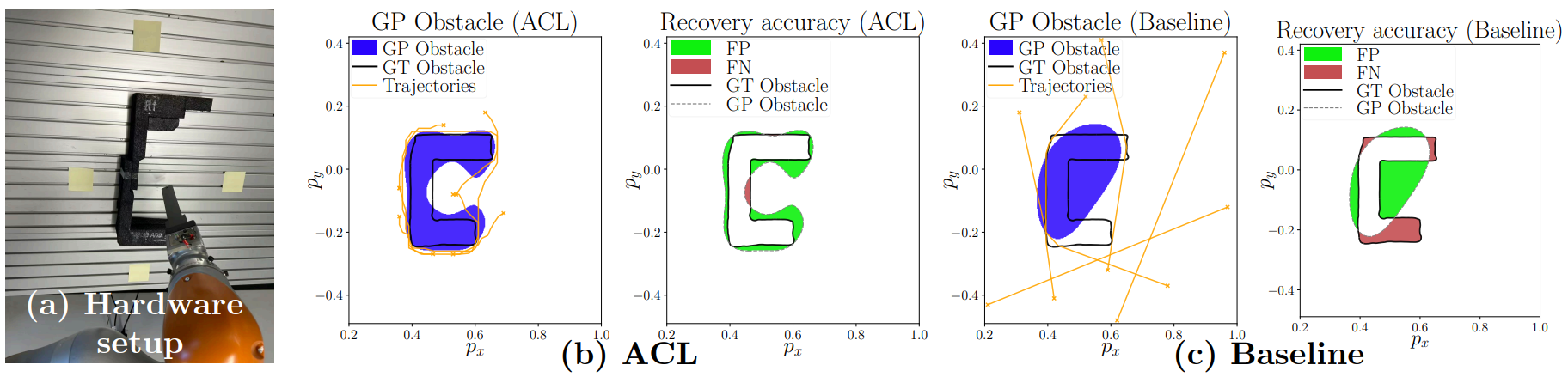
Abstract: We present an iterative active constraint learning (ACL) algorithm, within the learning from demonstrations (LfD) paradigm, which intelligently solicits informative demonstration trajectories for inferring an unknown constraint in the demonstrator's environment. Our approach iteratively trains a Gaussian process (GP) on the available demonstration dataset to represent the unknown constraints, uses the resulting GP posterior to query start/goal states, and generates informative demonstrations which are added to the dataset. Across simulation and hardware experiments using high-dimensional nonlinear dynamics and unknown nonlinear constraints, our method outperforms a baseline, random-sampling based method at accurately performing constraint inference from an iteratively generated set of sparse but informative demonstrations. |
||
BibTeX:
@inproceedings{Qiu-L4DC-26, |
||
 |
[C22] |
MAPS: Preserving Vision-Language Representations via Module-Wise Proximity Scheduling for Better Vision-Language-Action Generalization Chengyue Huang*, Mellon M. Zhang*, Robert Azarcon, Glen Chou, Zsolt Kira Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2026. [Abstract] [arXiv] [PDF] [Project Website] [Code] [Video] [Cite] |
Abstract: Vision-Language-Action (VLA) models inherit strong priors from pretrained Vision-Language Models (VLMs), but naive fine-tuning often disrupts these representations and harms generalization. Existing fixes -- freezing modules or applying uniform regularization -- either overconstrain adaptation or ignore the differing roles of VLA components. We present MAPS (Module-Wise Proximity Scheduling), the first robust fine-tuning framework for VLAs. Through systematic analysis, we uncover an empirical order in which proximity constraints should be relaxed to balance stability and flexibility. MAPS linearly schedules this relaxation, enabling visual encoders to stay close to their pretrained priors while action-oriented language layers adapt more freely. MAPS introduces no additional parameters or data, and can be seamlessly integrated into existing VLAs. Across MiniVLA-VQ, MiniVLA-OFT, OpenVLA-OFT, and challenging benchmarks such as SimplerEnv, CALVIN, LIBERO, as well as real-world evaluations on the Franka Emika Panda platform, MAPS consistently boosts both in-distribution and out-of-distribution performance (up to +30%). Our findings highlight empirically guided proximity to pretrained VLMs as a simple yet powerful principle for preserving broad generalization in VLM-to-VLA transfer. |
||
BibTeX:
@inproceedings{Huang-CVPR-26, |
||
 |
[C21] |
A Convex Formulation of Compliant Contact between Filaments and Rigid Bodies Wei-Chen Li, Glen Chou Proceedings of the 43rd IEEE International Conference on Robotics and Automation (ICRA), June 2026. [Abstract] [arXiv] [PDF] [Code] [Video] [Cite] |
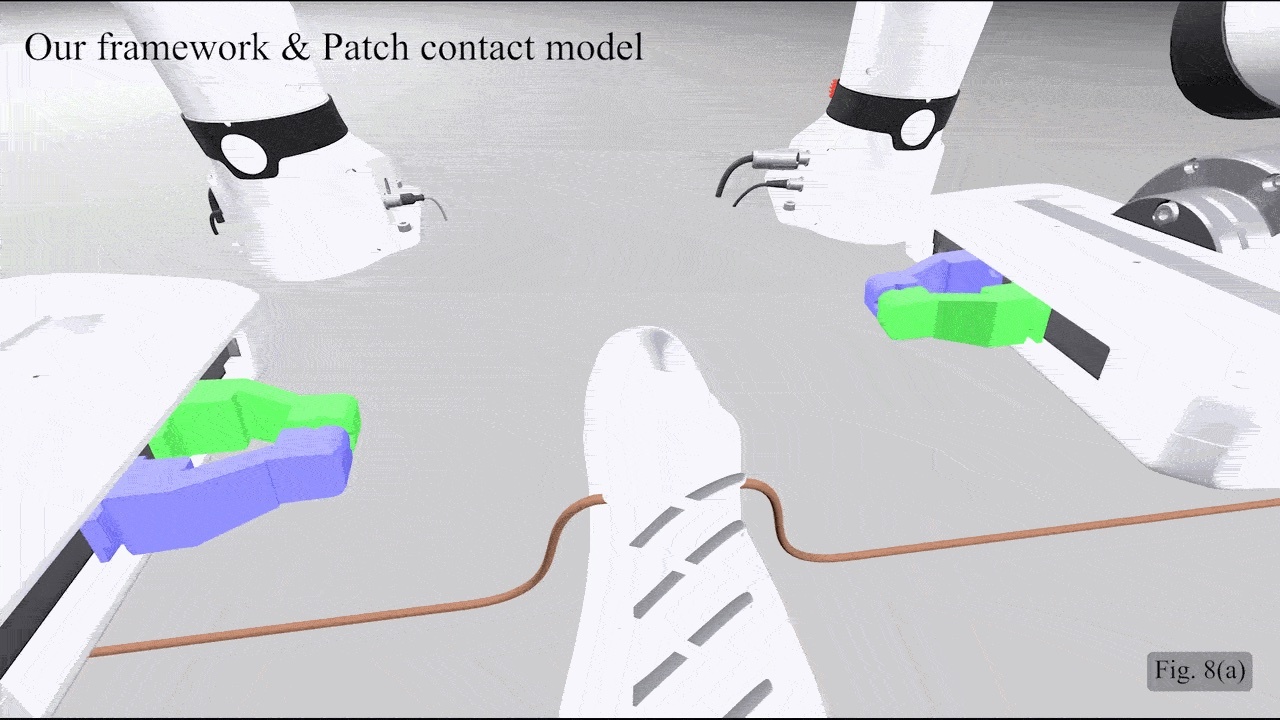
Abstract: We present a computational framework for simulating filaments interacting with rigid bodies through contact. Filaments are challenging to simulate due to their codimensionality, i.e., they are one-dimensional structures embedded in three-dimensional space. Existing methods often assume that filaments remain permanently attached to rigid bodies. Our framework unifies discrete elastic rod (DER) modeling, a pressure field patch contact model, and a convex contact formulation to accurately simulate frictional interactions between slender filaments and rigid bodies - capabilities not previously achievable. Owing to the convex formulation of contact, each time step can be solved to global optimality, guaranteeing complementarity between contact velocity and impulse. We validate the framework by assessing the accuracy of frictional forces and comparing its physical fidelity against baseline methods. Finally, we demonstrate its applicability in both soft robotics, such as a stochastic filament-based gripper, and deformable object manipulation, such as shoelace tying, providing a versatile simulator for systems involving complex filament-filament and filament-rigid body interactions. |
||
BibTeX:
@inproceedings{Li-ICRA-26, |
||
 |
[C20] |
Probabilistically-Safe Bipedal Navigation over Uncertain Terrain via Conformal Prediction and Contraction Analysis Kasidit Muenprasitivej, Ye Zhao, Glen Chou Proceedings of the 43rd IEEE International Conference on Robotics and Automation (ICRA), June 2026. [Abstract] [arXiv] [PDF] [Video] [Cite] |
Abstract: We address the challenge of enabling bipedal robots to traverse rough terrain by developing probabilistically safe planning and control strategies that ensure dynamic feasibility and centroidal robustness under terrain uncertainty. Specifically, we propose a high-level Model Predictive Control (MPC) navigation framework for a bipedal robot with a specified confidence level of safety that (i) enables safe traversal toward a desired goal location across a terrain map with uncertain elevations, and (ii) formally incorporates uncertainty bounds into the centroidal dynamics of locomotion control. To model the rough terrain, we employ Gaussian Process (GP) regression to estimate elevation maps and leverage Conformal Prediction (CP) to construct calibrated confidence intervals that capture the true terrain elevation. Building on this, we formulate contraction-based reachable tubes that explicitly account for terrain uncertainty, ensuring state convergence and tube invariance. In addition, we introduce a contraction-based flywheel torque control law for the reduced-order Linear Inverted Pendulum Model (LIPM), which stabilizes the angular momentum about the center-of-mass (CoM). This formulation provides both probabilistic safety and goal reachability guarantees. For a given confidence level, we establish the forward invariance of the proposed torque control law by demonstrating exponential stabilization of the actual CoM phase-space trajectory and the desired trajectory prescribed by the high-level planner. Finally, we evaluate the effectiveness of our planning framework through physics-based simulations of the Digit bipedal robot in MuJoCo. |
||
BibTeX:
@inproceedings{Muenprasitivej-ICRA-26, |
||
 |
[C19] |
Robustly Constrained Dynamic Games for Uncertain Nonlinear Dynamics Shuyu Zhan*, Chih-Yuan Chiu*, Antoine Leeman, Glen Chou Proceedings of the 43rd IEEE International Conference on Robotics and Automation (ICRA), June 2026. [Abstract] [arXiv] [PDF] [Code] [Video] [Cite] |
Abstract: We propose a novel framework for robust dynamic games with nonlinear dynamics corrupted by state-dependent additive noise, and nonlinear agent-specific and shared constraints. Leveraging system-level synthesis (SLS), each agent designs a nominal trajectory and a causal affine error feedback law to minimize their own cost while ensuring that its own constraints and the shared constraints are satisfied, even under worst-case noise realizations. Building on these nonlinear safety certificates, we define the novel notion of a robustly constrained Nash equilibrium (RCNE). We then present an Iterative Best Response (IBR)-based algorithm that iteratively refines the optimal trajectory and controller for each agent until approximate convergence to the RCNE. We evaluated our method on simulations and hardware experiments involving large numbers of robots with high-dimensional nonlinear dynamics, as well as state-dependent dynamics noise. Across all experiment settings, our method generated trajectory rollouts which robustly avoid collisions, while a baseline game-theoretic algorithm for producing open-loop motion plans failed to generate trajectories that satisfy constraints. |
||
BibTeX:
@inproceedings{Zhan-ICRA-26, |
||
 |
[C18] |
Formal Safety Verification and Refinement for Generative Motion Planners via Certified Local Stabilization Devesh Nath*, Haoran Yin*, Glen Chou Proceedings of the 43rd IEEE International Conference on Robotics and Automation (ICRA), June 2026. [Abstract] [arXiv] [PDF] [Video] [Cite] |
Abstract: We present a method for formal safety verification of learning-based generative motion planners. Generative motion planners (GMPs) offer advantages over traditional planners, but verifying the safety and dynamic feasibility of their outputs is difficult since neural network verification (NNV) tools scale only to a few hundred neurons, while GMPs often contain millions. To preserve GMP expressiveness while enabling verification, our key insight is to imitate the GMP by stabilizing references sampled from the GMP with a small neural tracking controller and then applying NNV to the closed-loop dynamics. This yields reachable sets that rigorously certify closed-loop safety, while the controller enforces dynamic feasibility. Building on this, we construct a library of verified GMP references and deploy them online in a way that imitates the original GMP distribution whenever it is safe to do so, improving safety without retraining. We evaluate across diverse planners, including diffusion, flow matching, and vision-language models, improving safety in simulation (on ground robots and quadcopters) and on hardware (differential-drive robot). |
||
BibTeX:
@inproceedings{Nath-ICRA-26, |
||
 |
[C17] |
NavMoE: Hybrid Model-and Learning-based Traversability Estimation for Local Navigation via Mixture of Experts Botao He*, Amir H. Shahidzadeh*, Yu Chen*, Jiayi Wu, Tianrui Guan, Guofei Chen, Howie Choset, Dinesh Manocha, Glen Chou, Cornelia Fermuller, Yiannis Aloimonos Proceedings of the 43rd IEEE International Conference on Robotics and Automation (ICRA), June 2026. [Abstract] [arXiv] [PDF] [Video] [Cite] |
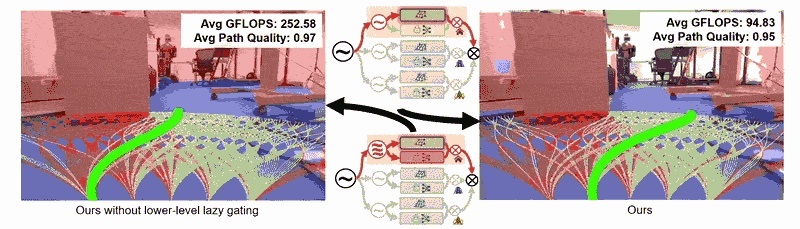
Abstract: This paper explores traversability estimation for robot navigation. A key bottleneck in traversability estimation lies in efficiently achieving reliable and robust predictions while accurately encoding both geometric and semantic information across diverse environments. We introduce Navigation via Mixture of Experts (NAVMOE), a hierarchical and modular approach for traversability estimation and local navigation. NAVMOE combines multiple specialized models for specific terrain types, each of which can be either a classical model-based or a learning-based approach that predicts traversability for specific terrain types. NAVMOE dynamically weights the contributions of different models based on the input environment through a gating network. Overall, our approach offers three advantages: First, NAVMOE enables traversability estimation to adaptively leverage specialized approaches for different terrains, which enhances generalization across diverse and unseen environments. Second, our approach significantly improves efficiency with negligible cost of solution quality by introducing a training-free lazy gating mechanism, which is designed to minimize the number of activated experts during inference. Third, our approach uses a two-stage training strategy that enables the training for the gating networks within the hybrid MoE method that contains nondifferentiable modules. Extensive experiments show that NAVMOE delivers a better efficiency and performance balance than any individual expert or full ensemble across different domains, improving cross-domain generalization and reducing average computational cost by 81.2% via lazy gating, with less than a 2% loss in path quality. |
||
BibTeX:
@inproceedings{He-ICRA-26, |
||
 |
[J8] |
Constraint Learning in Multi-Agent Dynamic Games from Demonstrations of Local Nash Interactions Zhouyu Zhang*, Chih-Yuan Chiu*, Glen Chou IEEE Robotics and Automation Letters (RA-L), with presentation at IROS 2026, vol. 11, no. 6, pp. 6696-6703, March 2026. [Abstract] [arXiv] [PDF] [DOI] [Supplementary Video] [Cite] |
Abstract: We present an inverse dynamic game-based algorithm to learn parametric constraints from a given dataset of local Nash equilibrium interactions between multiple agents. Specifically, we introduce mixed-integer linear programs (MILP) encoding the Karush-Kuhn-Tucker (KKT) conditions of the interacting agents, which recover constraints consistent with the local Nash stationarity of the interaction demonstrations. We establish theoretical guarantees that our method learns inner approximations of the true safe and unsafe sets. We also use the interaction constraints recovered by our method to design motion plans that robustly satisfy the underlying constraints. Across simulations and hardware experiments, our methods accurately inferred constraints and designed safe interactive motion plans for various classes of constraints, both convex and non-convex, from interaction demonstrations of agents with nonlinear dynamics. |
||
BibTeX:
@inproceedings{Zhang-RAL-26, |
||
 |
[C16] |
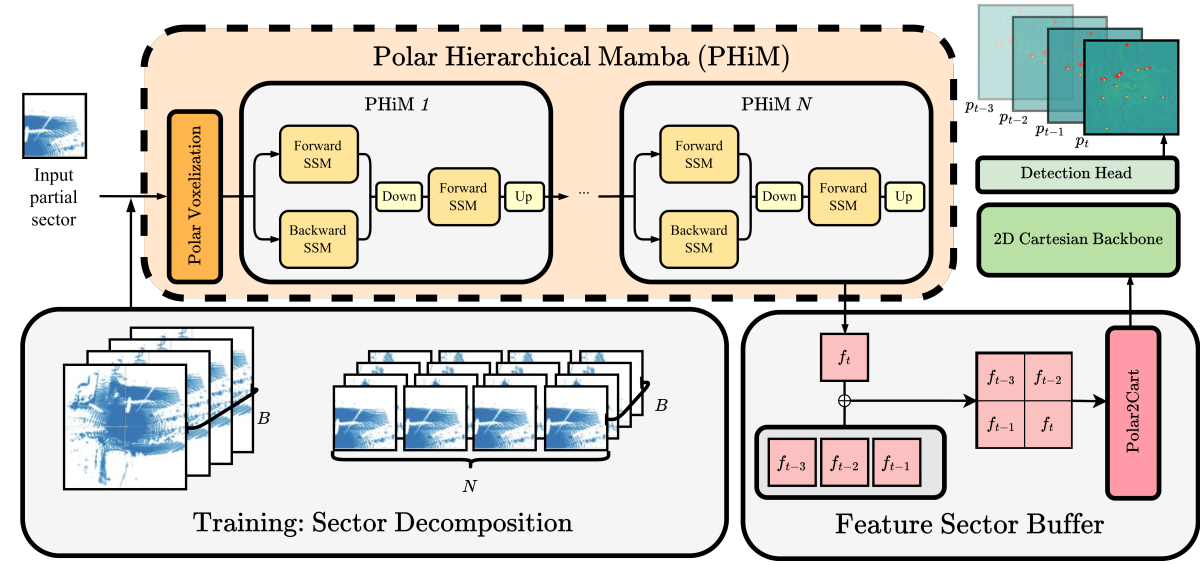
Towards Streaming LiDAR Object Detection with Point Clouds as Egocentric Sequences Mellon M. Zhang, Glen Chou*, Saibal Mukhopadhyay* Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), March 2026. [Abstract] [arXiv] [PDF] [Code] [Cite] |
Abstract: Accurate and low-latency 3D object detection is essential for autonomous driving, where safety hinges on both rapid response and reliable perception. While rotating LiDAR sensors are widely adopted for their robustness and fidelity, current detectors face a trade-off: streaming methods process partial polar sectors on the fly for fast updates but suffer from limited visibility, cross-sector dependencies, and distortions from retrofitted Cartesian designs, whereas fullscan methods achieve higher accuracy but are bottlenecked by the inherent latency of a LiDAR revolution. We propose Polar-Fast-Cartesian-Full (PFCF), a hybrid detector that combines fast polar processing for intra-sector feature extraction with accurate Cartesian reasoning for full-scene understanding. Central to PFCF is a custom Mamba SSMbased streaming backbone with dimensionally-decomposed convolutions that avoids distortion-heavy planes, enabling parameter-efficient, translation-invariant, and distortionrobust polar representation learning. Local sector features are extracted via this backbone, then accumulated into a sector feature buffer to enable efficient inter-sector communication through a full-scan backbone. PFCF establishes a new Pareto frontier on the Waymo Open dataset, surpassing prior streaming baselines by 10% mAP and matching full-scan accuracy at twice the update rate. Code is available at https://github.com/meilongzhang/PolarHierarchical-Mamba. |
||
BibTeX:
@inproceedings{Zhang-WACV-26, |
||
 |
[J7] |
Learning Constraints from Stochastic Partially-Observed Closed-Loop Demonstrations Chih-Yuan Chiu*, Zhouyu Zhang*, Glen Chou IEEE Control Systems Letters (L-CSS), with presentation at ACC 2026, vol. 10, pp. 43-48, January 2026. [Abstract] [arXiv] [PDF] [DOI] [Cite] |
Abstract: We present a method for learning unknown parametric constraints from locally-optimal input-output trajectory data. We assume the data is generated by rollouts of stochastic nonlinear dynamics, under a single state or output feedback law and initial condition but distinct noise realizations, to robustly satisfy underlying constraints despite worst-case noise outcomes. We encode the Karush-Kuhn-Tucker (KKT) conditions of this robust optimal feedback control problem within a feasibility problem to recover constraints consistent with the local optimality of the demonstrations. We prove that our constraint learning method (i) accurately recovers the demonstrator’s policy, and (ii) conservatively estimates the set of policies that ensure constraint satisfaction despite worst-case noise realizations. Moreover, we perform sensitivity analysis, proving that when demonstrations are corrupted by transmission error, the inaccuracy in the learned feedback law scales linearly in the error magnitude. Empirically, our method accurately recovers unknown constraints from simulated noisy, closed-loop demonstrations generated using dynamics, both linear and nonlinear, (e.g., unicycle and quadrotor) and a range of feedback mechanisms. |
||
BibTeX:
@inproceedings{Chiu-LCSS-26, |
||
 |
[C15] |
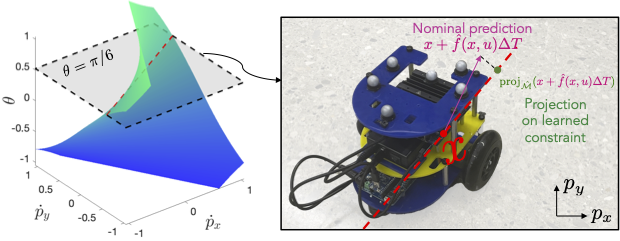
Improving Out-of-Distribution Generalization of Learned Dynamics by Learning Pseudometrics and Constraint Manifolds Yating Lin, Glen Chou, Dmitry Berenson Proceedings of the 61st IEEE International Conference on Robotics and Automation (ICRA), May 2024. [Abstract] [arXiv] [PDF] [Cite] |
Abstract: We propose a method for improving the prediction accuracy of learned robot dynamics models on out-of-distribution (OOD) states. We achieve this by leveraging two key sources of structure often present in robot dynamics: 1) sparsity, i.e., some components of the state may not affect the dynamics, and 2) physical limits on the set of possible motions, in the form of nonholonomic constraints. Crucially, we do not assume this structure is known a priori, and instead learn it from data. We use contrastive learning to obtain a distance pseudometric that uncovers the sparsity pattern in the dynamics, and use it to reduce the input space when learning the dynamics. We then learn the unknown constraint manifold by approximating the normal space of possible motions from the data, which we use to train a Gaussian process (GP) representation of the constraint manifold. We evaluate our approach on a physical differential-drive robot and a simulated quadrotor, showing improved prediction accuracy on OOD data relative to baselines. |
||
BibTeX:
@inproceedings{Lin-ICRA-24, |
||
 |
[C14] |
Synthesizing Stable Reduced-Order Visuomotor Policies for Nonlinear Systems via Sums-of-Squares Optimization Glen Chou, Russ Tedrake Proceedings of the 62nd IEEE Conference on Decision and Control (CDC), December 2023. [Abstract] [arXiv] [PDF] [Cite] |
Abstract: We present a method for synthesizing dynamic, reduced-order output-feedback polynomial control policies for control-affine nonlinear systems which guarantees runtime stability to a goal state, when using visual observations and a learned perception module in the feedback control loop. We leverage Lyapunov analysis to formulate the problem of synthesizing such policies. This problem is nonconvex in the policy parameters and the Lyapunov function that is used to prove the stability of the policy. To solve this problem approximately, we propose two approaches: the first solves a sequence of sum-of-squares optimization problems to iteratively improve a policy which is provably-stable by construction, while the second directly performs gradient-based optimization on the parameters of the polynomial policy, and its closed-loop stability is verified a posteriori. We extend our approach to provide stability guarantees in the presence of observation noise, which realistically arises due to errors in the learned perception module. We evaluate our approach on several underactuated nonlinear systems, including pendula and quadrotors, showing that our guarantees translate to empirical stability when controlling these systems from images, while baseline approaches can fail to reliably stabilize the system. |
||
BibTeX:
@inproceedings{Chou-CDC-23, |
||
 |
[C13] |
Fighting Uncertainty with Gradients: Offline Reinforcement Learning via Diffusion Score Matching H.J. Terry Suh, Glen Chou*, Hongkai Dai*, Lujie Yang*, Abhishek Gupta, Russ Tedrake 7th Conference on Robot Learning (CoRL), November 2023. [Abstract] [arXiv] [PDF] [Supplementary Video] [Code] [Website] [Cite] |
Abstract: Offline optimization paradigms such as offline Reinforcement Learning (RL) or Imitation Learning (IL) allow policy search algorithms to make use of offline data, but require careful incorporation of uncertainty in order to circumvent the challenges of distribution shift. Gradient-based policy search methods are a promising direction due to their effectiveness in high dimensions; however, we require a more careful consideration of how these methods interplay with uncertainty estimation. We claim that in order for an uncertainty metric to be amenable for gradient-based optimization, it must be (i) stably convergent to data when uncertainty is minimized with gradients, and (ii) not prone to underestimation of true uncertainty. We investigate smoothed distance to data as a metric, and show that it not only stably converges to data, but also allows us to analyze model bias with Lipschitz constants. Moreover, we establish an equivalence between smoothed distance to data and data likelihood, which allows us to use score-matching techniques to learn gradients of distance to data. Importantly, we show that offline model-based policy search problems that maximize data likelihood do not require values of likelihood; but rather only the gradient of the log likelihood (the score function). Using this insight, we propose Score-Guided Planning (SGP), a planning algorithm for offline RL that utilizes score-matching to enable first-order planning in high-dimensional problems, where zeroth-order methods were unable to scale, and ensembles were unable to overcome local minima. |
||
BibTeX:
@inproceedings{Suh-CoRL-23, |
||
 |
[C12] |
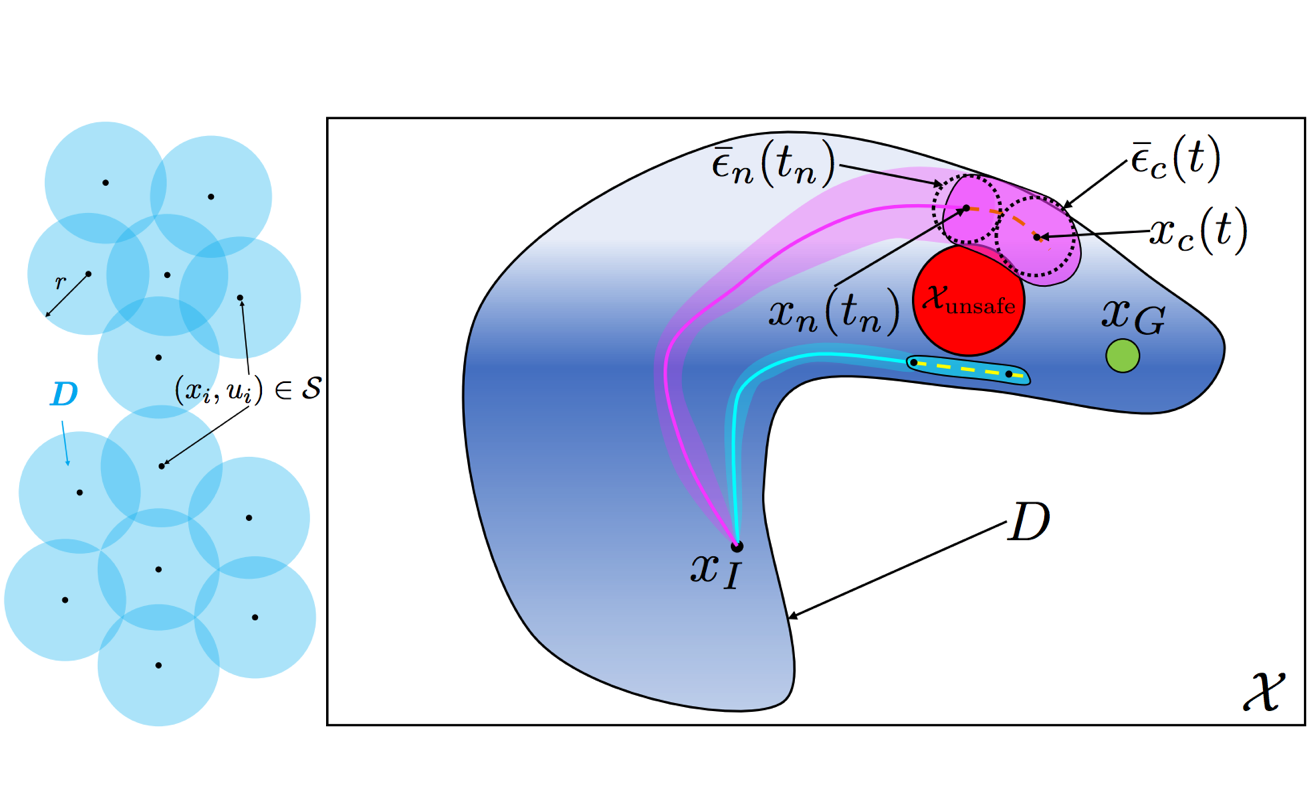
Statistical Safety and Robustness Guarantees for Feedback Motion Planning of Unknown Underactuated Stochastic Systems Craig Knuth, Glen Chou, Jamie Reese, Joseph Moore Proceedings of the 60th IEEE International Conference on Robotics and Automation (ICRA), May 2023. [Abstract] [arXiv] [PDF] [Cite] |
Abstract: We present a method for providing statistical guarantees on runtime safety and goal reachability for integrated planning and control of a class of systems with unknown nonlinear stochastic underactuated dynamics. Specifically, given a dynamics dataset, our method jointly learns a mean dynamics model, a spatially-varying disturbance bound that captures the effect of noise and model mismatch, and a feedback controller based on contraction theory that stabilizes the learned dynamics. We propose a sampling-based planner that uses the mean dynamics model and simultaneously bounds the closed-loop tracking error via a learned disturbance bound. We employ techniques from Extreme Value Theory (EVT) to estimate, to a specified level of confidence, several constants which characterize the learned components and govern the size of the tracking error bound. This ensures plans are guaranteed to be safely tracked at runtime. We validate that our guarantees translate to empirical safety in simulation on a 10D quadrotor, and in the real world on a physical CrazyFlie quadrotor and Clearpath Jackal robot, whereas baselines that ignore the model error and stochasticity are unsafe. |
||
BibTeX:
@inproceedings{Knuth-ICRA-23, |
||
 |
[C11] |
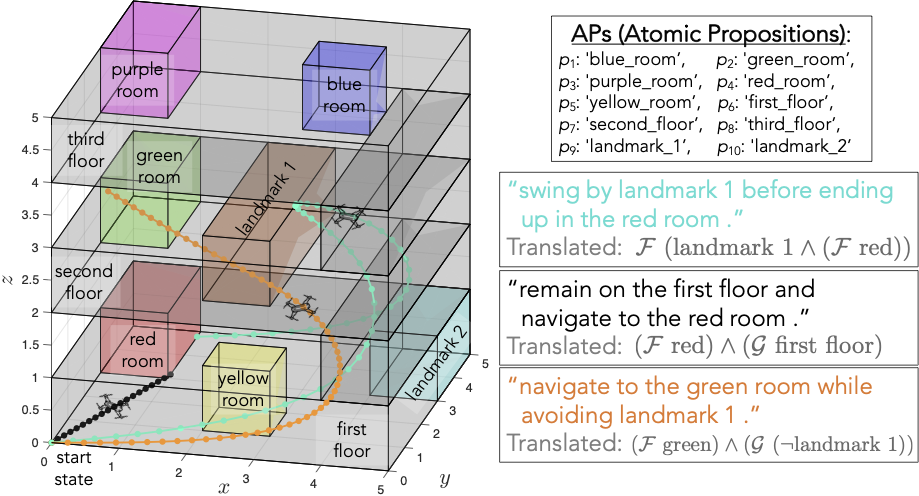
Data-Efficient Learning of Natural Language to Linear Temporal Logic Translators for Robot Task Specification Jiayi Pan, Glen Chou, Dmitry Berenson Proceedings of the 60th IEEE International Conference on Robotics and Automation (ICRA), May 2023. [Abstract] [arXiv] [PDF] [Supplementary Video] [Code] [Cite] |
Abstract: To make robots accessible to a broad audience, it is critical to endow them with the ability to take universal modes of communication, like commands given in natural language, and extract a concrete desired task specification, defined using a formal language like linear temporal logic (LTL). In this paper, we present a learning-based approach for translating from natural language commands to LTL specifications with very limited human-labeled training data. This is in stark contrast to existing natural-language to LTL translators, which require large human-labeled datasets, often in the form of labeled pairs of LTL formulas and natural language commands, to train the translator. To reduce reliance on human data, our approach generates a large synthetic training dataset through algorithmic generation of LTL formulas, conversion to structured English, and then exploiting the paraphrasing capabilities of modern large language models (LLMs) to synthesize a diverse corpus of natural language commands corresponding to the LTL formulas. We use this generated data to finetune an LLM and apply a constrained decoding procedure at inference time to ensure the returned LTL formula is syntactically correct. We evaluate our approach on three existing LTL/natural language datasets and show that we can translate natural language commands at 75% accuracy with far less human data (≤12 annotations). Moreover, when training on large human-annotated datasets, our method achieves higher test accuracy (95% on average) than prior work. Finally, we show the translated formulas can be used to plan long-horizon, multi-stage tasks on a 12D quadrotor. |
||
BibTeX:
@inproceedings{Pan-ICRA-23, |
||
 |
[C10] |
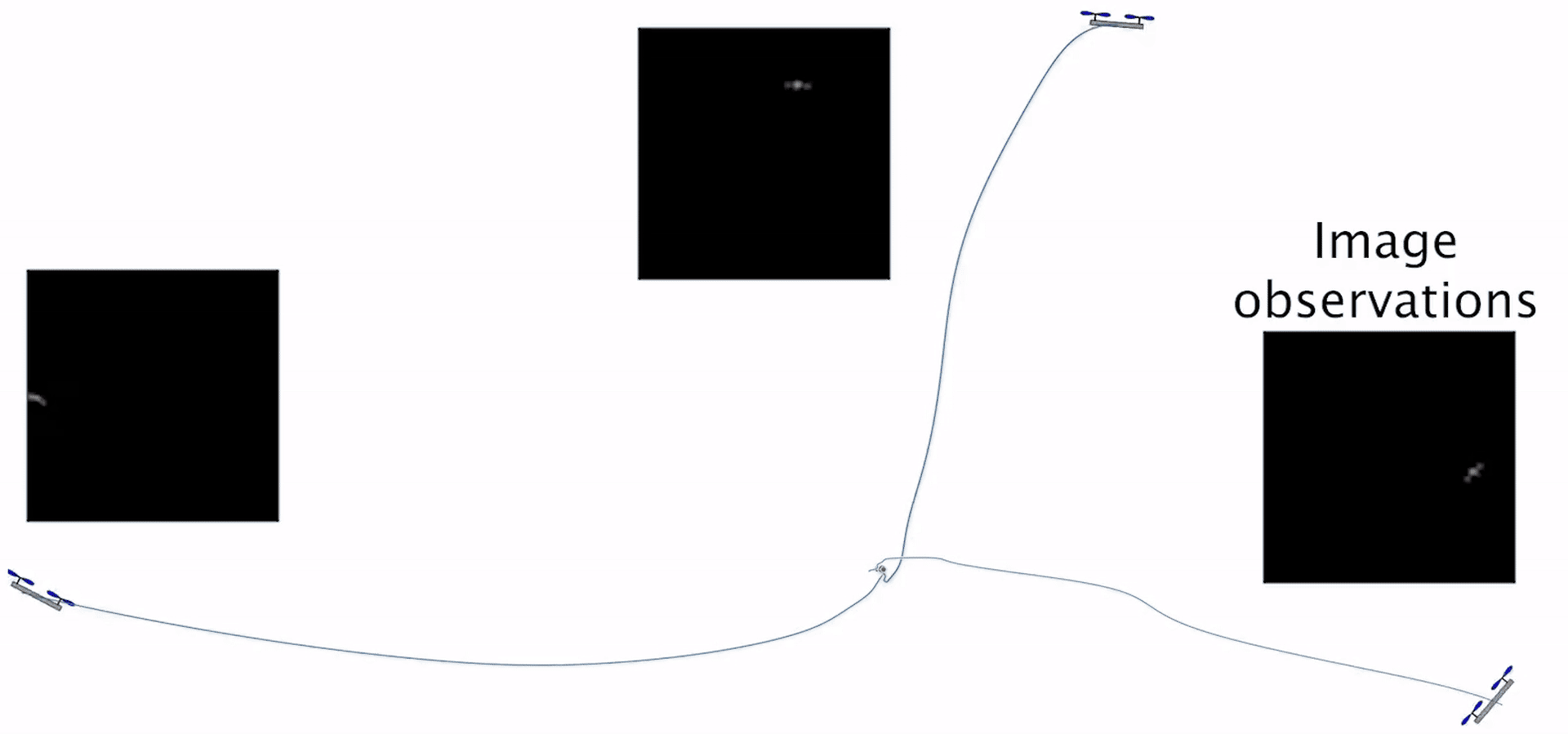
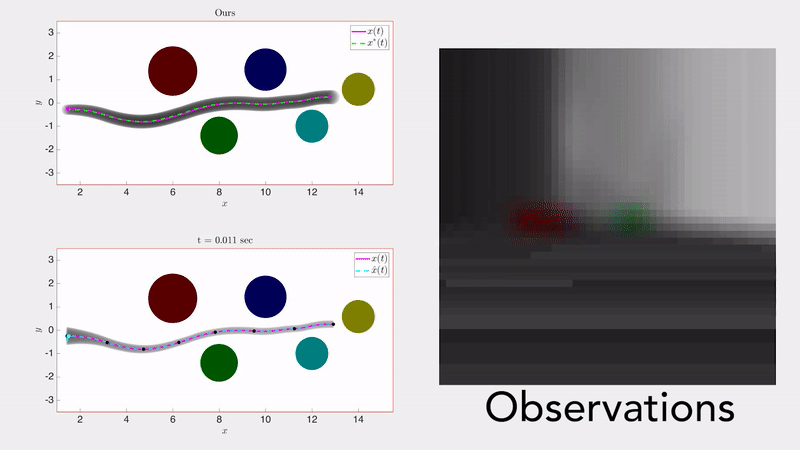
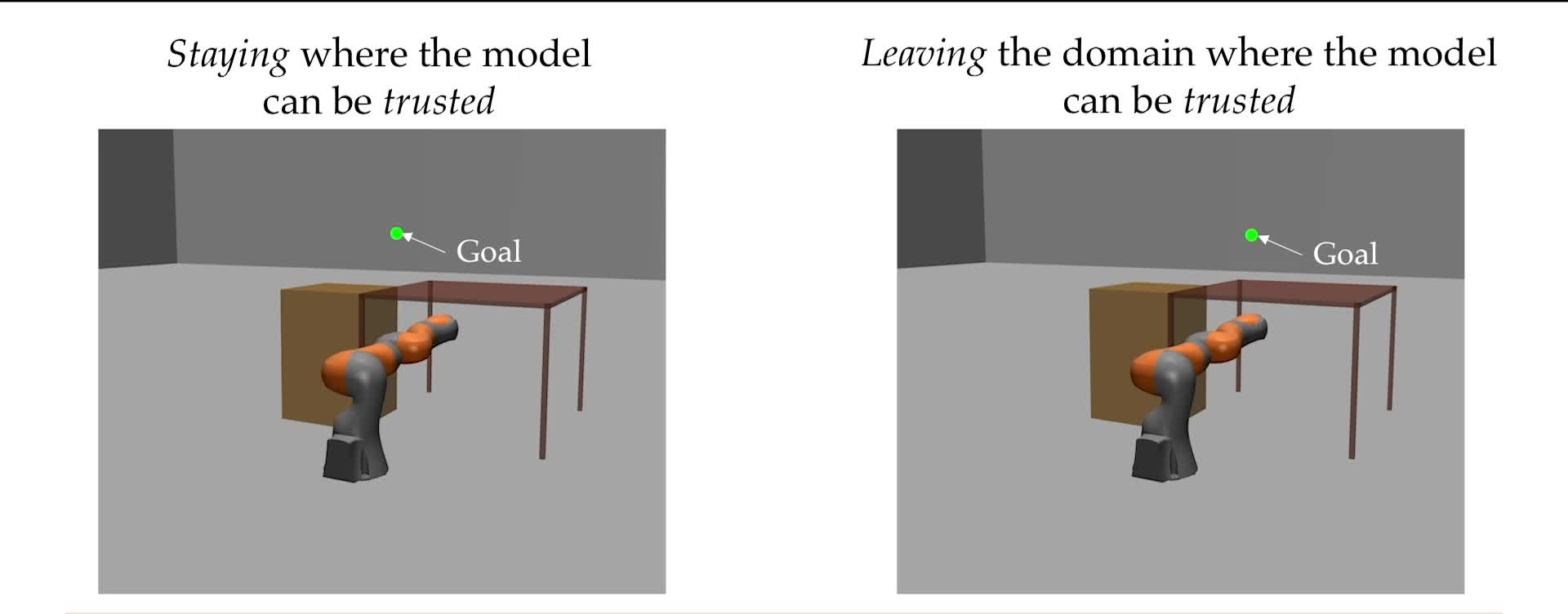
Safe Output Feedback Motion Planning from Images via Learned Perception Modules and Contraction Theory Glen Chou, Necmiye Ozay, Dmitry Berenson Proceedings of the 15th International Workshop on the Algorithmic Foundations of Robotics (WAFR), June 2022. [Abstract] [arXiv] [DOI] [Talk] [Cite] |
Abstract: We present a motion planning algorithm for a class of uncertain control-affine nonlinear systems which guarantees runtime safety and goal reachability when using high-dimensional sensor measurements (e.g., RGB-D images) and a learned perception module in the feedback control loop. First, given a dataset of states and observations, we train a perception system that seeks to invert a subset of the state from an observation, and estimate an upper bound on the perception error which is valid with high probability in a trusted domain near the data. Next, we use contraction theory to design a stabilizing state feedback controller and a convergent dynamic state observer which uses the learned perception system to update its state estimate. We derive a bound on the trajectory tracking error when this controller is subjected to errors in the dynamics and incorrect state estimates. Finally, we integrate this bound into a sampling-based motion planner, guiding it to return trajectories that can be safely tracked at runtime using sensor data. We demonstrate our approach in simulation on a 4D car, a 6D planar quadrotor, and a 17D manipulation task with RGB(-D) sensor measurements, demonstrating that our method safely and reliably steers the system to the goal, while baselines that fail to consider the trusted domain or state estimation errors can be unsafe. |
||
BibTeX:
@inproceedings{Chou-WAFR-22, |
||
 |
[J6] |
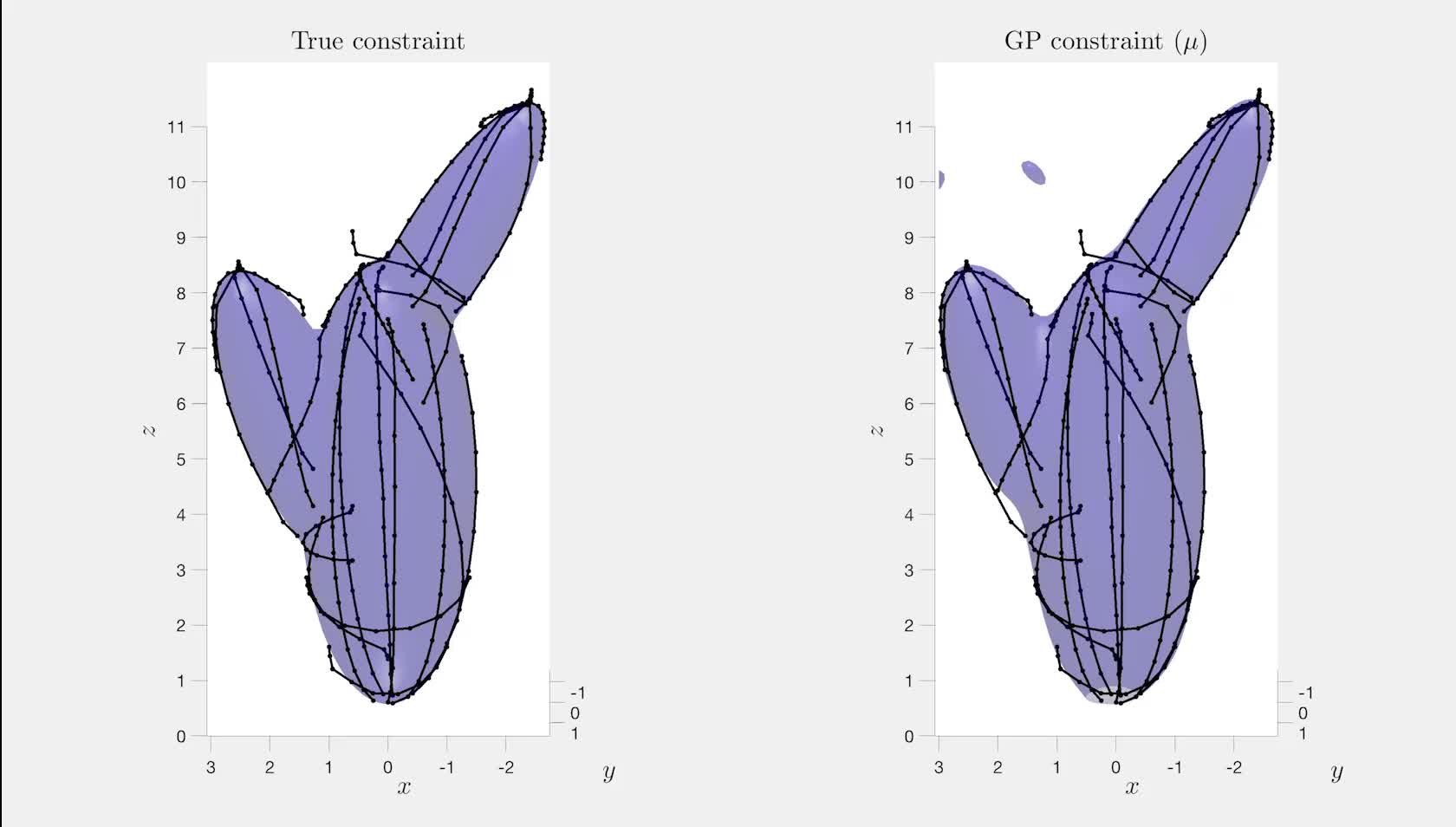
Gaussian Process Constraint Learning for Scalable Chance-Constrained Motion Planning From Demonstrations Glen Chou*, Hao Wang*, Dmitry Berenson IEEE Robotics and Automation Letters (RA-L), with presentation at ICRA 2022, vol. 7, no. 2, pp. 3827-3834, April 2022. [Abstract] [arXiv] [DOI] [Supplementary Video] [Cite] |
Abstract: We propose a method for learning constraints represented as Gaussian processes (GPs) from locally-optimal demonstrations. Our approach uses the Karush-Kuhn-Tucker (KKT) optimality conditions to determine where on the demonstrations the constraint is tight, and a scaling of the constraint gradient at those states. We then train a GP representation of the constraint which is consistent with and which generalizes this information. We further show that the GP uncertainty can be used within a kinodynamic RRT to plan probabilistically-safe trajectories, and that we can exploit the GP structure within the planner to exactly achieve a specified safety probability. We demonstrate our method can learn complex, nonlinear constraints demonstrated on a 5D nonholonomic car, a 12D quadrotor, and a 3-link planar arm, all while requiring minimal prior information on the constraint. Our results suggest the learned GP constraint is accurate, outperforming previous constraint learning methods that require more a priori knowledge. |
||
BibTeX:
@inproceedings{Chou-RAL-22, |
||
 |
[J5] |
Learning Temporal Logic Formulas from Suboptimal Demonstrations: Theory and Experiments Glen Chou, Necmiye Ozay, Dmitry Berenson Autonomous Robots (AURO), vol. 46, no. 1, pp. 149-174, January 2022. [Abstract] [DOI] [Supplementary Video] [Cite] |
Abstract: We present a method for learning multi-stage tasks from demonstrations by learning the logical structure and atomic propositions of a consistent linear temporal logic (LTL) formula. The learner is given successful but potentially suboptimal demonstrations, where the demonstrator is optimizing a cost function while satisfying the LTL formula, and the cost function is uncertain to the learner. Our algorithm uses the Karush-Kuhn-Tucker (KKT) optimality conditions of the demonstrations together with a counterexample-guided falsification strategy to learn the atomic proposition parameters and logical structure of the LTL formula, respectively. We provide theoretical guarantees on the conservativeness of the recovered atomic proposition sets, as well as completeness in the search for finding an LTL formula consistent with the demonstrations. We evaluate our method on high-dimensional nonlinear systems by learning LTL formulas explaining multi-stage tasks on a simulated 7-DOF arm and a quadrotor, and show that it outperforms competing methods for learning LTL formulas from positive examples. Finally, we demonstrate that our approach can learn a real-world multi-stage tabletop manipulation task on a physical 7-DOF Kuka iiwa arm. |
||
BibTeX:
@inproceedings{Chou-AURO-21, |
||
 |
[C9] |
Model Error Propagation via Learned Contraction Metrics for Safe Feedback Motion Planning of Unknown Systems Glen Chou, Necmiye Ozay, Dmitry Berenson Proceedings of the 60th IEEE Conference on Decision and Control (CDC), December 2021. [Abstract] [arXiv] [DOI] [Supplementary Video] [Cite] |
Abstract: We present a method for contraction-based feedback motion planning of locally incrementally exponentially stabilizable systems with unknown dynamics that provides probabilistic safety and reachability guarantees. Given a dynamics dataset, our method learns a deep control-affine approximation of the dynamics. To find a trusted domain where this model can be used for planning, we obtain an estimate of the Lipschitz constant of the model error, which is valid with a given probability, in a region around the training data, providing a local, spatially-varying model error bound. We derive a trajectory tracking error bound for a contraction-based controller that is subjected to this model error, and then learn a controller that optimizes this tracking bound. With a given probability, we verify the correctness of the controller and tracking error bound in the trusted domain. We then use the trajectory error bound together with the trusted domain to guide a sampling-based planner to return trajectories that can be robustly tracked in execution. We show results on a 4D car, a 6D quadrotor, and a 22D deformable object manipulation task, showing our method plans safely with learned models of high-dimensional underactuated systems, while baselines that plan without considering the tracking error bound or the trusted domain can fail to stabilize the system and become unsafe. |
||
BibTeX:
@inproceedings{Chou-CDC-21, |
||
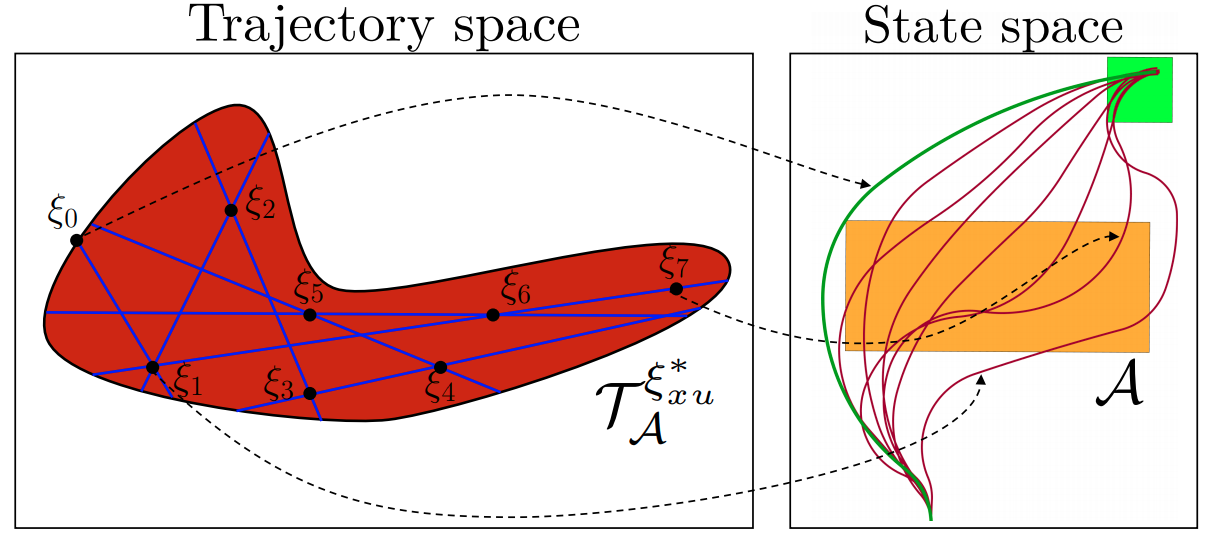 |
[J4] |
Learning Constraints from Demonstrations with Grid and Parametric Representations Glen Chou, Dmitry Berenson, Necmiye Ozay International Journal of Robotics Research (IJRR), vol. 40, no. 10-11, pp. 1255-1283, September 2021. [Abstract] [DOI] [Cite] |
Abstract: We extend the learning from demonstration paradigm by providing a method for learning unknown constraints shared across tasks, using demonstrations of the tasks, their cost functions, and knowledge of the system dynamics and control constraints. Given safe demonstrations, our method uses hit-and-run sampling to obtain lower cost, and thus unsafe, trajectories. Both safe and unsafe trajectories are used to obtain a consistent representation of the unsafe set via solving an integer program. Our method generalizes across system dynamics and learns a guaranteed subset of the constraint. Additionally, by leveraging a known parameterization of the constraint, we modify our method to learn parametric constraints in high dimensions. We also provide theoretical analysis on what subset of the constraint and safe set can be learnable from safe demonstrations. We demonstrate our method on linear and nonlinear system dynamics, show that it can be modified to work with suboptimal demonstrations, and that it can also be used to learn constraints in a feature space. |
||
BibTeX:
@inproceedings{Chou-IJRR-21, |
||
 |
[J3] |
Planning with Learned Dynamics: Probabilistic Guarantees on Safety and Reachability via Lipschitz Constants Craig Knuth*, Glen Chou*, Necmiye Ozay, Dmitry Berenson IEEE Robotics and Automation Letters (RA-L), with presentation at ICRA 2021, vol. 6, no. 3, pp. 5129-5136, July 2021. [Abstract] [arXiv] [DOI] [Supplementary Video] [Cite] |
Abstract: We present a method for feedback motion planning of systems with unknown dynamics which provides probabilistic guarantees on safety, reachability, and goal stability. To find a domain in which a learned control-affine approximation of the true dynamics can be trusted, we estimate the Lipschitz constant of the difference between the true and learned dynamics, and ensure the estimate is valid with a given probability. Provided the system has at least as many controls as states, we also derive existence conditions for a one-step feedback law which can keep the real system within a small bound of a nominal trajectory planned with the learned dynamics. Our method imposes the feedback law existence as a constraint in a sampling-based planner, which returns a feedback policy around a nominal plan ensuring that, if the Lipschitz constant estimate is valid, the true system is safe during plan execution, reaches the goal, and is ultimately invariant in a small set about the goal. We demonstrate our approach by planning using learned models of a 6D quadrotor and a 7DOF Kuka arm. We show that a baseline which plans using the same learned dynamics without considering the error bound or the existence of the feedback law can fail to stabilize around the plan and become unsafe. |
||
BibTeX:
@inproceedings{Knuth-RAL-21, |
||
 |
[C8] |
Compositional Safety Rules for Inter-Triggering Hybrid Automata Kwesi J. Rutledge*, Glen Chou*, Necmiye Ozay Proceedings of the 24th International Conference on Hybrid Systems: Computation and Control (HSCC), May 2021. [Abstract] [PDF] [DOI] [Supplementary Video] [Cite] |
Abstract: In this paper, we present a compositional condition for ensuring safety of a collection of interacting systems modeled by inter-triggering hybrid automata (ITHA). ITHA is a modeling formalism for representing multi-agent systems in which each agent is governed by individual dynamics but can also interact with other agents through triggering actions. These triggering actions result in a jump/reset in the state of other agents according to a global resolution function. A sufficient condition for safety of the collection, inspired by responsibility-sensitive safety, is developed in two parts: self-safety relating to the individual dynamics, and responsibility relating to the triggering actions. The condition relies on having an over-approximation method for the resolution function. We further show how such over-approximations can be obtained and improved via communication. We use two examples, a job scheduling task on parallel processors and a highway driving example, throughout the paper to illustrate the concepts. Finally, we provide a comprehensive evaluation on how the proposed condition can be leveraged for several multi-agent control and supervision examples. |
||
BibTeX:
@inproceedings{Rutledge-HSCC-21, |
||
 |
[C7] |
Uncertainty-Aware Constraint Learning for Adaptive Safe Motion Planning from Demonstrations Glen Chou, Necmiye Ozay, Dmitry Berenson Proceedings of the 4th Conference on Robot Learning (CoRL), November 2020. [Abstract] [arXiv] [PDF] [Talk] [Supplementary Video] [Cite] |
Abstract: We present a method for learning to satisfy uncertain constraints from demonstrations. Our method uses robust optimization to obtain a belief over the potentially infinite set of possible constraints consistent with the demonstrations, and then uses this belief to plan trajectories that trade off performance with satisfying the possible constraints. We use these trajectories in a closed-loop policy that executes and replans using belief updates, which incorporate data gathered during execution. We derive guarantees on the accuracy of our constraint belief and probabilistic guarantees on plan safety. We present results on a 7-DOF arm and 12D quadrotor, showing our method can learn to satisfy high-dimensional (up to 30D) uncertain constraints, and outperforms baselines in safety and efficiency. |
||
BibTeX:
@inproceedings{Chou-CoRL-20, |
||
 |
[C6] |
Explaining Multi-stage Tasks by Learning Temporal Logic Formulas from Suboptimal Demonstrations Glen Chou, Necmiye Ozay, Dmitry Berenson Proceedings of Robotics: Science and Systems (RSS) XVI, July 2020. [Abstract] [arXiv] [DOI] [Talk] [Supplementary Video] [Cite] Invited to AURO special issue. |
Abstract: We present a method for learning multi-stage tasks from demonstrations by learning the logical structure and atomic propositions of a consistent linear temporal logic (LTL) formula. The learner is given successful but potentially suboptimal demonstrations, where the demonstrator is optimizing a cost function while satisfying the LTL formula, and the cost function is uncertain to the learner. Our algorithm uses the Karush-Kuhn-Tucker (KKT) optimality conditions of the demonstrations together with a counterexample-guided falsification strategy to learn the atomic proposition parameters and logical structure of the LTL formula, respectively. We provide theoretical guarantees on the conservativeness of the recovered atomic proposition sets, as well as completeness in the search for finding an LTL formula consistent with the demonstrations. We evaluate our method on high-dimensional nonlinear systems by learning LTL formulas explaining multi-stage tasks on 7-DOF arm and quadrotor systems and show that it outperforms competing methods for learning LTL formulas from positive examples. |
||
BibTeX:
@inproceedings{Chou-RSS-20, |
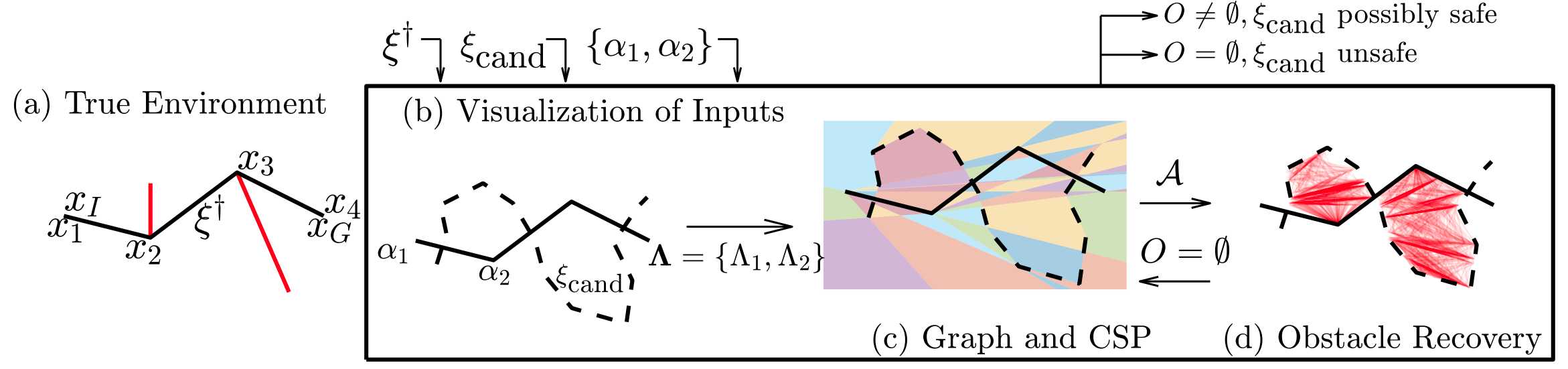
||
 |
[C5] |
Inferring Obstacles and Path Validity from Visibility-Constrained Demonstrations Craig Knuth, Glen Chou, Necmiye Ozay, Dmitry Berenson Proceedings of the 14th International Workshop on the Algorithmic Foundations of Robotics (WAFR), June 2020. [Abstract] [arXiv] [DOI] [Cite] |
Abstract: Many methods in learning from demonstration assume that the demonstrator has knowledge of the full environment. However, in many scenarios, a demonstrator only sees part of the environment and they continuously replan as they gather information. To plan new paths or to reconstruct the environment, we must consider the visibility constraints and replanning process of the demonstrator, which, to our knowledge, has not been done in previous work. We consider the problem of inferring obstacle configurations in a 2D environment from demonstrated paths for a point robot that is capable of seeing in any direction but not through obstacles. Given a set of \textit{survey points}, which describe where the demonstrator obtains new information, and a candidate path, we construct a Constraint Satisfaction Problem (CSP) on a cell decomposition of the environment. We parameterize a set of obstacles corresponding to an assignment from the CSP and sample from the set to find valid environments. We show that there is a probabilistically-complete, yet not entirely tractable, algorithm that can guarantee novel paths in the space are unsafe or possibly safe. We also present an incomplete, but empirically-successful, heuristic-guided algorithm that we apply in our experiments to 1) planning novel paths and 2) recovering a probabilistic representation of the environment. |
||
BibTeX:
@inproceedings{Knuth-WAFR-20, |
||
 |
[J2] |
Learning Constraints from Locally-Optimal Demonstrations under Cost Function Uncertainty Glen Chou, Necmiye Ozay, Dmitry Berenson IEEE Robotics and Automation Letters (RA-L), with presentation at ICRA 2020, vol. 5, no. 2, pp. 3682-3690, April 2020. [Abstract] [arXiv] [DOI] [Supplementary Video] [Cite] |
Abstract: We present an algorithm for learning parametric constraints from locally-optimal demonstrations, where the cost function being optimized is uncertain to the learner. Our method uses the Karush-Kuhn-Tucker (KKT) optimality conditions of the demonstrations within a mixed integer linear program (MILP) to learn constraints which are consistent with the local optimality of the demonstrations, by either using a known constraint parameterization or by incrementally growing a parameterization that is consistent with the demonstrations. We provide theoretical guarantees on the conservativeness of the recovered safe/unsafe sets and analyze the limits of constraint learnability when using locally-optimal demonstrations. We evaluate our method on high-dimensional constraints and systems by learning constraints for 7-DOF arm and quadrotor examples, show that it outperforms competing constraint-learning approaches, and can be effectively used to plan new constraint-satisfying trajectories in the environment. |
||
BibTeX:
@inproceedings{Chou-RAL-20, |
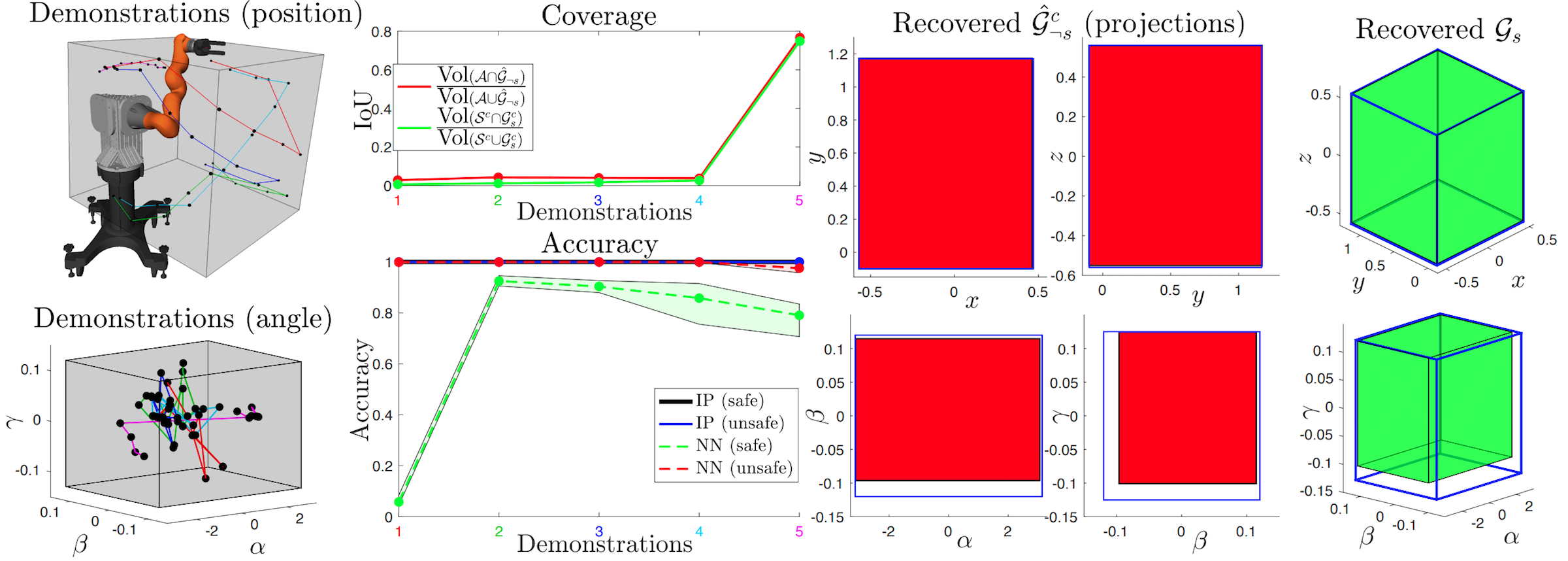
||
 |
[C4] |
Learning Parametric Constraints in High Dimensions from Demonstrations Glen Chou, Necmiye Ozay, Dmitry Berenson Proceedings of the 3rd Conference on Robot Learning (CoRL), November 2019. [Abstract] [arXiv] [PDF] [Cite] |
Abstract: We present a scalable algorithm for learning parametric constraints in high dimensions from safe expert demonstrations. To reduce the ill-posedness of the constraint recovery problem, our method uses hit-and-run sampling to generate lower cost, and thus unsafe, trajectories. Both safe and unsafe trajectories are used to obtain a representation of the unsafe set that is compatible with the data by solving an integer program in that representation's parameter space. Our method can either leverage a known parameterization or incrementally grow a parameterization while remaining consistent with the data, and we provide theoretical guarantees on the conservativeness of the recovered unsafe set. We evaluate our method on high-dimensional constraints for high-dimensional systems by learning constraints for 7-DOF arm, quadrotor, and planar pushing examples, and show that our method outperforms baseline approaches. |
||
BibTeX:
@inproceedings{Chou-CoRL-19, |
||
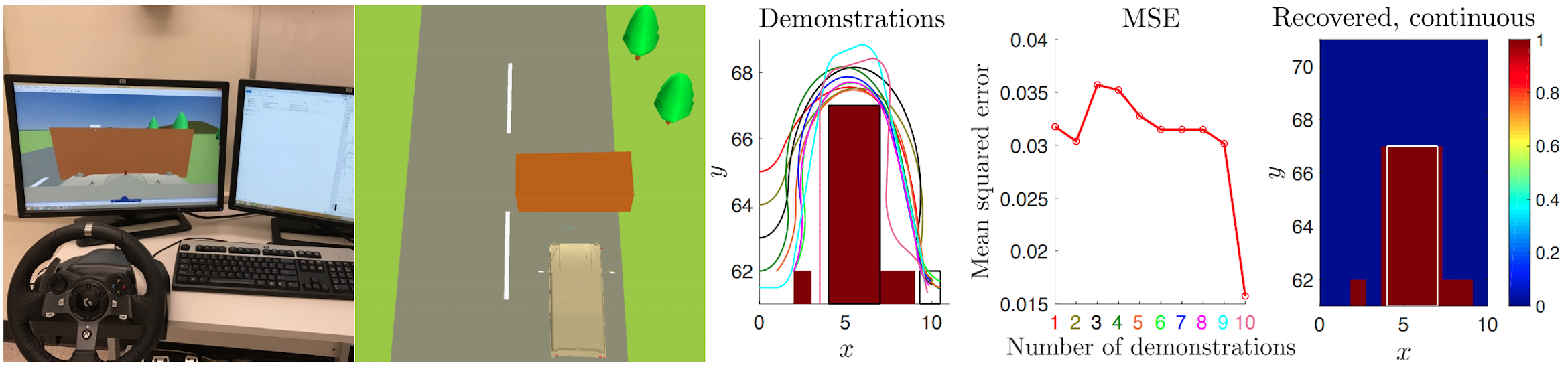 |
[C3] |
Learning Constraints from Demonstrations Glen Chou, Dmitry Berenson, Necmiye Ozay Proceedings of the 14th International Workshop on the Algorithmic Foundations of Robotics (WAFR), December 2018. [Abstract] [arXiv] [DOI] [Cite] Invited to IJRR special issue. |
Abstract: We extend the learning from demonstration paradigm by providing a method for learning unknown constraints shared across tasks, using demonstrations of the tasks, their cost functions, and knowledge of the system dynamics and control constraints. Given safe demonstrations, our method uses hit-and-run sampling to obtain lower cost, and thus unsafe, trajectories. Both safe and unsafe trajectories are used to obtain a consistent representation of the unsafe set via solving an integer program. Our method generalizes across system dynamics and learns a guaranteed subset of the constraint. We also provide theoretical analysis on what subset of the constraint can be learnable from safe demonstrations. We demonstrate our method on linear and nonlinear system dynamics, show that it can be modi ed to work with suboptimal demonstrations, and that it can also be used to solve a transfer learning task. |
||
BibTeX:
@inproceedings{Chou-WAFR-18, |
||
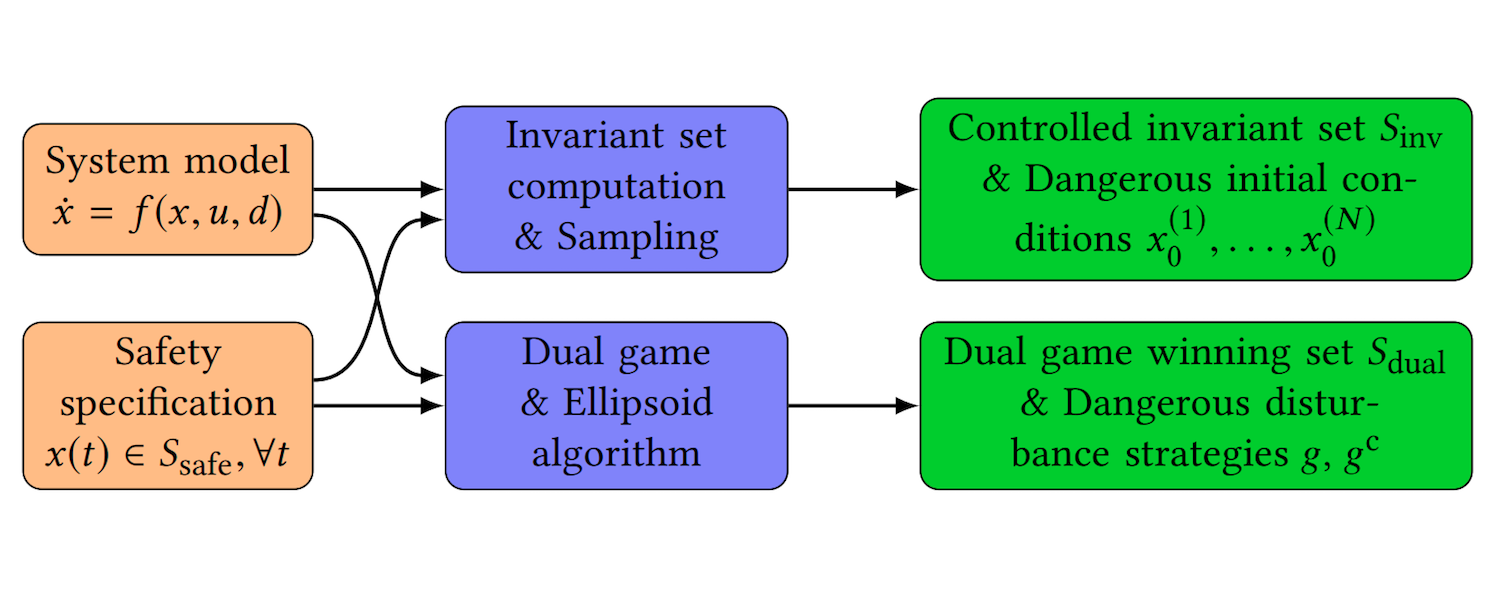 |
[J1] |
Using control synthesis to generate corner cases: A case study on autonomous driving Glen Chou*, Yunus E. Sahin*, Liren Yang*, Kwesi J. Rutledge, Petter Nilsson, Necmiye Ozay IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (ESWEEK-TCAD special issue), vol. 37, no. 11, pp. 2906-2917, November 2018. [Abstract] [arXiv] [DOI] [Cite] Also presented at 2018 University of Michigan Engineering Graduate Symposium; won Emerging Research Social Impact award. |
Abstract: This paper employs correct-by-construction control synthesis, in particular controlled invariant set computations, for falsification. Our hypothesis is that if it is possible to compute a “large enough" controlled invariant set either for the actual system model or some simplification of the system model, interesting corner cases for other control designs can be generated by sampling initial conditions from the boundary of this controlled invariant set. Moreover, if falsifying trajectories for a given control design can be found through such sampling, then the controlled invariant set can be used as a supervisor to ensure safe operation of the control design under consideration. In addition to interesting initial conditions, which are mostly related to safety violations in transients, we use solutions from a dual game, a reachability game for the safety specification, to find falsifying inputs. We also propose optimization-based heuristics for input generation for cases when the state is outside the winning set of the dual game. To demonstrate the proposed ideas, we consider case studies from basic autonomous driving functionality, in particular, adaptive cruise control and lane keeping. We show how the proposed technique can be used to find interesting falsifying trajectories for classical control designs like proportional controllers, proportional integral controllers and model predictive controllers, as well as an open source real-world autonomous driving package. |
||
BibTeX:
@article{Chou-et-al-Journal-18, |
||
Notes: Also presented at 2018 University of Michigan Engineering Graduate Symposium; won Emerging Research Social Impact award. |
||
 |
[C2] |
Incremental Segmentation of ARX Models Glen Chou, Necmiye Ozay, Dmitry Berenson Proceedings of the 18th IFAC Symposium on System Identification (SYSID), July 2018. [Abstract] [PDF] [DOI] [Cite] |
Abstract: We consider the problem of incrementally segmenting auto-regressive models with exogenous inputs (ARX models) when the data is received sequentially at run-time. In particular, we extend a recently proposed dynamic programming based polynomial-time algorithm for offline (batch) ARX model segmentation to the incremental setting. The new algorithm enables sequential updating of the models, eliminating repeated computation, while remaining optimal. We also show how certain noise bounds can be used to detect switches automatically at run-time. The efficiency of the approach compared to the batch method is illustrated on synthetic and real data. |
||
BibTeX:
@inproceedings{Chou-SYSID-18, |
||
 |
[C1] |
A Hybrid Framework for Multi-Vehicle Collision Avoidance Aparna Dhinakaran*, Mo Chen*, Glen Chou, Jennifer C. Shih, Claire J. Tomlin Proceedings of the 56th IEEE Conference on Decision and Control (CDC), December 2017. [Abstract] [arXiv] [DOI] [Cite] |
Abstract: With the recent surge of interest in UAVs for civilian services, the importance of developing tractable multi-agent analysis techniques that provide safety and performance guarantees have drastically increased. Hamilton-Jacobi (HJ) reachability has successfully provided these guarantees to small-scale systems and is flexible in terms of system dynamics. However, the exponential complexity scaling of HJ reachability with respect to system dimension prevents its direct application to larger-scale problems where the number of vehicles is greater than two. In this paper, we propose a collision avoidance algorithm using a hybrid framework for N+1 vehicles through higher-level control logic given any N-vehicle collision avoidance algorithm. Our algorithm conservatively approximates a guaranteed-safe region in the joint state space of the N+1 vehicles and produces a safety-preserving controller. In addition, our algorithm does not incur significant additional computation cost. We demonstrate our proposed method in simulation. |
||
BibTeX:
@inproceedings{Dhinakaran-et-al-CDC-17,
author = {Aparna Dhinakaran and
Mo Chen and
Glen Chou and
Jennifer C. Shih and
Claire J. Tomlin},
title = {A hybrid framework for multi-vehicle collision avoidance},
booktitle = {56th {IEEE} Annual Conference on Decision and Control, {CDC} 2017,
Melbourne, Australia, December 12-15, 2017},
pages = {2979--2984},
year = {2017}, |
||
Theses
| |
Safe End-to-end Learning-based Robot Autonomy via Integrated Perception, Planning, and Control Glen Chou PhD thesis, University of Michigan, August 2022. [Abstract] [PDF] [Cite] |
|
Abstract: Trustworthy robots must be able to complete tasks reliably while obeying safety constraints. While traditional methods for constrained motion planning and optimal control can achieve this if the environment is accurately modeled and the task is unambiguous, future robots will be deployed in unstructured settings with poorly-understood or inaccurate dynamics, observation models, and task specifications. Thus, to plan and perform control, robots will invariably need data to learn and refine their understanding of their environments and tasks. Though machine learning provides a means to obtain perception and dynamics models from data, blindly trusting these potentially-unreliable models when planning can cause unsafe and unpredictable behavior at runtime. To this end, this dissertation is motivated by the following questions: (1) To refine their understanding of the desired task, how can robots learn components of a constrained motion planner (e.g., constraints, task specifications) in a data-efficient manner? and (2) How can robots quantify and remain robust to the inevitable uncertainty and error in learned components within the broader perception-planning-control autonomy loop in order to provide system-level guarantees on safety and task completion at runtime?
To address the first question, we propose methods that use successful human demonstrations to learn unknown constraints and task specifications. The crux of this problem relies on learning what not to do (i.e., behavior violating the unknown constraints or specifications) from only successful examples. We make the insight that the demonstrations' approximate optimality implicitly defines what the robot should not do, and that this information can be extracted by simulating lower-cost trajectories and by using the Karush-Kuhn-Tucker (KKT) optimality conditions. These strong optimality priors make our method highly data-efficient. We use these methods to learn a broad class of constraints, including nonconvex obstacle constraints, and linear temporal logic formulas, which can describe complex temporally-extended robotic tasks. We demonstrate that our constraint-learning methods scale to high-dimensional systems, e.g., learning to complete novel constrained navigation tasks for a simulated 12D quadrotor and multi-stage manipulation tasks on a 7DOF arm (both simulated and in the real world).
To address the second question, we develop methods addressing uncertainty in A) constraints learned from demonstrations and B) dynamics models and perception modules learned from data. To quantify constraint uncertainty, we extract the set of constraints that are consistent with the demonstrations' KKT conditions (i.e., a belief over constraints), which is done by solving a sequence of robust mixed integer programs. We show that the robot can plan probabilistically-safe trajectories using this constraint belief, which can be updated using constraint data gathered in execution. To address uncertainty when planning with learned dynamics models of underactuated systems controlled with high-dimensional (image) observations, we estimate bounds on the error of the learned models inside a domain around their training data. Using tools from contraction theory, we propagate this model error bound into a trajectory tracking error bound. This tracking bound is used to constrain the planner to only return plans that can be safely tracked, with high probability, in spite of the errors in the perception and dynamics. We demonstrate that these theoretical guarantees translate to success in simulation, enabling safe task completion at runtime on a variety of challenging high-dimensional, underactuated systems using rich sensor observations (e.g., RGB-D images) in the feedback control loop. |
||
BibTeX:
@inproceedings{Chou-Thesis-25, |
||
Refereed Workshop Papers/Technical Reports
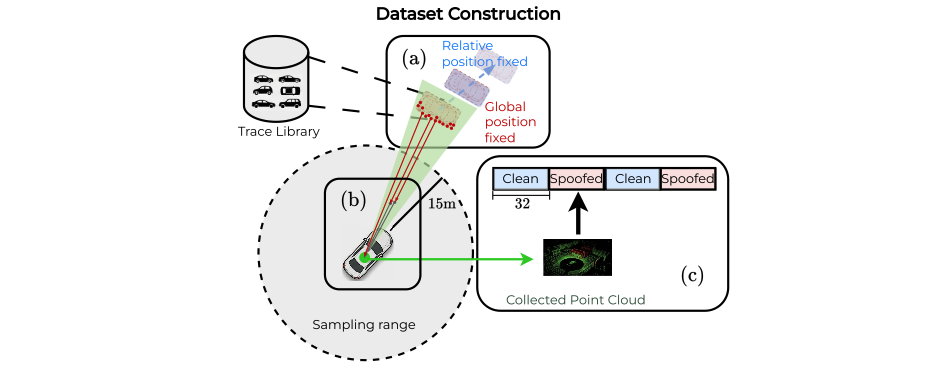 |
[W7] |
On the Adversarial Robustness of Temporal LiDAR Object Detectors Mellon M. Zhang*, Siddhant Panse*, Akshal Dhal, Rishit Sarkar, Zimo Fan, Glen Chou CVPR SPAR-3D Workshop: Security, Privacy, and Adversarial Robustness in 3D Generative Vision Models, June 2026. [Abstract] [PDF] [Cite] Best paper award, third place. |
|
Abstract: Accurate 3D object detection is critical for autonomous driving, yet robustness to adversarial attacks -- such as LiDAR spoofing -- remains underexplored. While recent LiDAR-based detectors leverage temporal context to improve performance, they are only evaluated under benign conditions. In this work, we introduce ATLAS (Adversarial Temporal LiDAR Attack Suite), a large-scale, physically grounded benchmark for evaluating spoofing attacks on temporal detectors. ATLAS simulates realistic sensor-level attacks by injecting structured adversarial point clouds into multi-frame sequences. Our results reveal a counterintuitive trend: temporal models are consistently more vulnerable than single-frame baselines, with attack success rates increasing with memory length. We further observe systematic overconfidence on spoofed objects, indicating a failure to distinguish corrupted history from reliable inputs. Together, these findings show that temporal aggregation -- when built on the assumption of clean observations -- becomes a liability under adversarial perturbations, motivating the need for uncertainty-aware temporal perception. |
|||
BibTeX:
@inproceedings{Zhang-CVPR-SPAR3D-26, |
|||
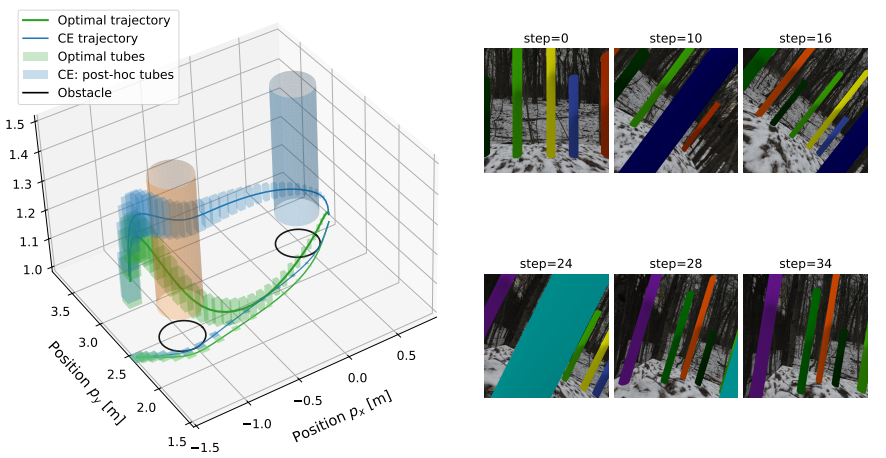 |
[W6] |
Epistemically Aware Predictive Visuomotor Control Antoine P. Leeman, Shuyu Zhan, Melanie Zeilinger*, Glen Chou* EurIPS Workshop on Epistemic Intelligence in Machine Learning, December 2025. [Abstract] [PDF] [Cite] |
|
Abstract: We design a safe visuomotor controller when perception is epistemically ambiguous due to occlusions, textureless regions, or distribution shift. Our approach is to replace point state estimates from images with credal (uncertainty) sets that a controller can leverage in real-time. To this end, we learn credal sets: a reduced measurement together with a state-dependent confidence set. We then design an ambiguity-aware output-feedback controller based on system level synthesis that treats it as a source of measurement ambiguity, propagates it through closed-loop responses, and enforces safety via uncertainty propagation and constraint tightening. The resulting pipeline links perception to control through sets, yielding certificates conditioned on coverage and naturally encouraging reducing epistemic uncertainty behavior. An efficient sequential convex programming implementation with Riccati recursions enables real-time control. In high-fidelity vision-based simulations of a car and a quadcopter, our method achieves safe trajectories in seconds while avoiding overconfidence under epistemic shift. |
|||
BibTeX:
@inproceedings{Leeman-EurIPS-25, |
|||
| |
[W5] |
Polar Hierarchical Mamba: Towards Streaming LiDAR Object Detection with Point Clouds as Egocentric Sequences Mellon M. Zhang, Glen Chou IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 4D Vision Workshop, June 2025. [Abstract] [PDF] [Cite] |
|
Abstract: Accurate and efficient object detection is a crucial component for fully autonomous self-driving. LiDAR sensors are employed to augment or replace cameras for more robustness in diverse driving situations, making object detection on LiDAR point clouds a critical area of research and improvement. Traditional approaches to LiDAR object detection wait for a full 360 degree turn of the scanning sensor before processing the entire point cloud in one go, introducing significant latency and lowering throughput. Previous streaming approaches use the raw LiDAR polar coordinate system to process egocentric partial scans of point clouds, but rely on translation-invariant convolutions, which are incompatible with polar coordinates and lead to performance degradation. In this paper, we show that the reliance on convolutions is not necessary and propose a Mamba-only backbone with Polar Hierarchical Mamba (PHiM) blocks, aggregating per-point features within each partial scan with a local bidirectional state space model and capturing higher-level global features in a streaming fashion with a global forward state space model. Our model on the Waymo Open dataset demonstrates 10% performance improvement from the previous leading polar-based detector, featuring state of the art performance among all polar-based methods while being competitive with existing Cartesian-based detectors with a 2x improvement in processing throughput evaluated as predictions per second. |
|||
BibTeX:
@inproceedings{Zhang-CVPR4DV-25, |
|||
 |
[W4] |
Safely Integrating Perception, Planning, and Control for Robust Learning-Based Robot Autonomy Glen Chou Robotics: Science and Systems, Pioneers Workshop, June 2022. [Abstract] [PDF] [Cite] |
|
Abstract: |
|||
BibTeX:
@inproceedings{Chou-RSSPioneersWS-22, |
|||
| |
[W3] |
Gaussian Process Constraint Learning for Scalable Safe Motion Planning from Demonstrations Hao Wang*, Glen Chou*, Dmitry Berenson Robotics: Science and Systems, Workshop on Integrating Planning and Learning, July 2021. [Abstract] [PDF] [Cite] |
|
Abstract: We propose a method for learning constraints represented as Gaussian processes (GPs) from locally-optimal demonstrations. Our approach uses the Karush-Kuhn-Tucker (KKT) optimality conditions of the demonstrations to determine the location and shape of the constraints, and uses these to train a GP which is consistent with this information. We demonstrate our method on a 12D quadrotor constraint learning problem, showing that the learned constraint is accurate and can be used within a kinodynamic RRT to plan probabilistically-safe trajectories. |
|||
BibTeX:
@inproceedings{Wang-RSSWS-21, |
|||
| |
[W2] |
Learning Parametric Constraints in High Dimensions from Demonstrations Glen Chou, Dmitry Berenson, Necmiye Ozay Robotics: Science and Systems, Workshop on Robust Autonomy, June 2019. [Abstract] [PDF] [Cite] Selected for long contributed talk. |
|
Abstract: We extend the learning from demonstration paradigm by providing a method for learning unknown constraints shared across tasks, using demonstrations of the tasks, their cost functions, and knowledge of the system dynamics and control constraints. Given safe demonstrations, our method uses hit-and-run sampling to obtain lower cost, and thus unsafe, trajectories. Both safe and unsafe trajectories are used to obtain a consistent representation of the unsafe set via solving a mixed integer program. Additionally, by leveraging a known parameterization of the constraint, we modify our method to learn parametric constraints in high dimensions. We show that our method can learn a six-dimensional pose constraint for a 7-DOF robot arm. |
|||
BibTeX:
@inproceedings{Chou-RSSWS-19, |
|||
 |
[W1] |
Using neural networks to compute approximate and guaranteed feasible Hamilton-Jacobi-Bellman PDE solutions Frank Jiang*, Glen Chou*, Mo Chen*, Claire J. Tomlin arXiv, November 2016. [Abstract] [arXiv] [Cite] |
|
Abstract: To sidestep the curse of dimensionality when computing solutions to Hamilton-Jacobi-Bellman partial differential equations (HJB PDE), we propose an algorithm that leverages a neural network to approximate the value function. We show that our final approximation of the value function generates near optimal controls which are guaranteed to successfully drive the system to a target state. Our framework is not dependent on state space discretization, leading to a significant reduction in computation time and space complexity in comparison with dynamic programming-based approaches. Using this grid-free approach also enables us to plan over longer time horizons with relatively little additional computation overhead. Unlike many previous neural network HJB PDE approximating formulations, our approximation is strictly conservative and hence any trajectories we generate will be strictly feasible. For demonstration, we specialize our new general framework to the Dubins car model and discuss how the framework can be applied to other models with higher-dimensional state spaces. |
|||
BibTeX:
@inproceedings{Jiang-et-al-16,
author = {Frank J. Jiang and
Glen Chou and
Mo Chen and
Claire J. Tomlin},
title = {Using neural networks to compute approximate and guaranteed feasible Hamilton-Jacobi-Bellman PDE solutions},
journal = {CoRR},
volume = {abs/1611.03158},
year = {2016}, |
|||